AI infrastructure refers to the specialized hardware, software, and networking systems required to build, train, deploy, and operate artificial intelligence applications at scale.
Most organizations today struggle with AI implementation because traditional computing systems can’t handle the massive computational demands of machine learning workloads. Modern AI models require thousands of simultaneous calculations, process terabytes of data, and need specialized processors designed for parallel operations.

Source: ResearchGate
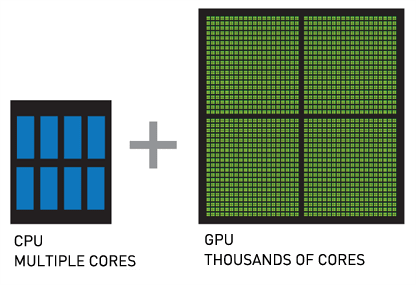
The infrastructure supporting AI differs fundamentally from standard business computing. While regular applications might use a few CPU cores sequentially, AI training can utilize thousands of GPU cores simultaneously to process neural network calculations.
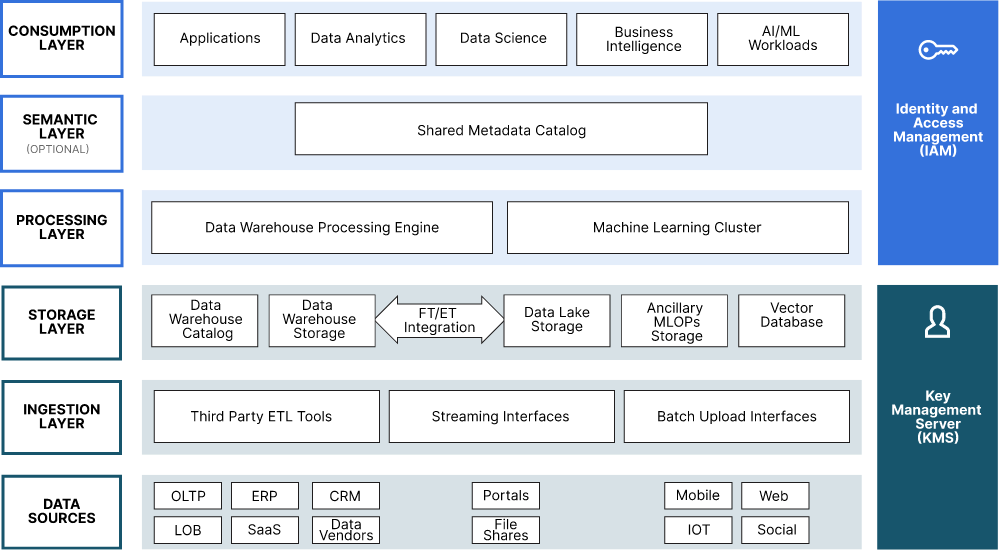
Enterprise AI deployments require coordinated systems spanning data storage, specialized computing hardware, machine learning software frameworks, and robust networking capabilities. Organizations that understand these infrastructure requirements can deploy AI solutions effectively, while those using inadequate infrastructure face performance bottlenecks, cost overruns, and failed implementations.
What Makes AI Infrastructure Different

Source: ResearchGate
AI infrastructure handles workloads that traditional IT systems weren’t designed for. Regular business applications process information one step at a time, but AI systems perform thousands of mathematical operations simultaneously. This parallel processing requirement changes everything about how the infrastructure works.
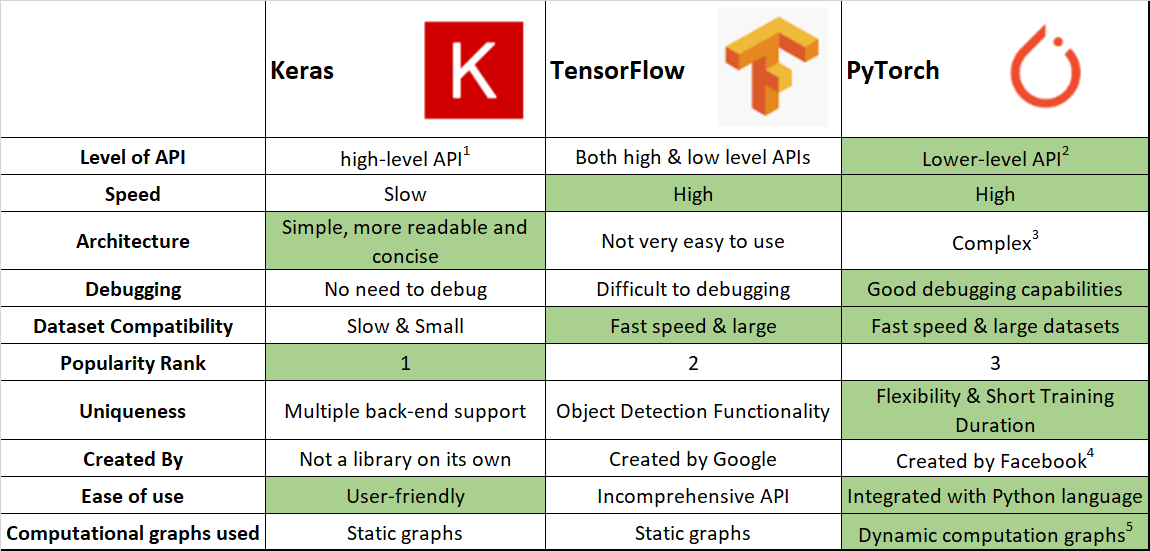
Traditional servers work well for email, databases, and web hosting. But training an AI model to recognize images or understand language requires processing millions of calculations at once. The hardware needs graphics processing units (GPUs) instead of just regular processors, and the software needs specialized frameworks like TensorFlow or PyTorch.
The data requirements also differ dramatically. Business applications typically work with structured information in databases, while AI systems process massive amounts of unstructured data — images, text, audio, and video files that can reach terabytes in size.
Core Components That Power AI Systems
Computing Hardware for AI Workloads
Source: Softwareg.com.au
GPUs serve as the primary computational engine for most AI applications. Originally designed for video game graphics, these processors contain thousands of small cores that excel at the matrix operations neural networks require. A single GPU can have over 10,000 cores working simultaneously, compared to a traditional CPU’s 8 to 64 cores.
Tensor Processing Units (TPUs) represent Google’s specialized processors built specifically for machine learning. These chips optimize for tensor operations — the multidimensional arrays that form the foundation of neural network computations. TPUs can train large language models faster and more efficiently than general-purpose processors.
Data Processing Units (DPUs) handle networking, storage, and security tasks separately from the main AI computations. This specialization allows GPUs and TPUs to focus entirely on AI calculations while DPUs manage data movement and infrastructure operations.
Storage and Data Management
Source: MinIO Blog
AI applications require storage systems that can handle both massive scale and high-speed access. Data lakes store any type of information without requiring predefined structure, accommodating the images, text, and multimedia content that AI systems process.
Distributed storage spreads data across multiple servers to support parallel access patterns. When training an AI model, different processors can read separate portions of a dataset simultaneously, preventing storage bottlenecks that would slow down the entire operation.
High-performance storage technologies like NVMe solid-state drives deliver the rapid data access speeds necessary for AI workloads. Training operations often involve reading terabytes of data repeatedly, requiring storage systems optimized for sustained high throughput.
Software Frameworks and Platforms
Source: GoPenAI
Machine learning frameworks provide the building blocks for AI development:
- TensorFlow — Google’s comprehensive platform for building and deploying AI models across different devices
- PyTorch — Meta’s framework popular for research due to its flexible, Python-like programming approach
- Scikit-learn — Focused on traditional machine learning algorithms for classification and regression tasks
- Apache Spark MLlib — Handles large-scale data processing and machine learning across distributed computing clusters
Container technologies like Docker package AI applications with their dependencies, ensuring consistent operation across different computing environments. Kubernetes manages collections of containers automatically, handling resource allocation, scaling, and failure recovery for AI applications.
AI Infrastructure Deployment Models

Source: B EYE
Cloud-Based AI Infrastructure
Cloud platforms offer immediate access to AI resources without large upfront investments. Organizations can provision GPU clusters, use managed AI services, and scale resources based on actual demand. Major cloud providers offer specialized AI services that handle infrastructure complexity automatically.
Cloud deployment works well for organizations experimenting with AI or those with variable workloads. Development teams can access cutting-edge hardware and software without managing physical infrastructure. This approach is particularly beneficial for small businesses looking to implement AI solutions without significant capital investment.
On-Premises AI Infrastructure
Organizations choose on-premises infrastructure for data control, security compliance, or consistent workloads. This approach requires purchasing specialized hardware, implementing software systems, and training staff to manage the infrastructure.
On-premises deployment suits organizations with sensitive data, regulatory requirements, or predictable AI workloads that can justify the infrastructure investment.
Hybrid AI Infrastructure
Hybrid approaches combine cloud and on-premises resources to optimize both performance and cost. Organizations might keep sensitive data on-premises while using cloud resources for additional computing power during peak training periods.
This model allows organizations to maintain data control while accessing elastic cloud resources when needed.
Implementation Strategy and Planning
Assessment and Requirements Planning
Organizations start by evaluating their current infrastructure capabilities. This assessment examines existing hardware, software, networking, and data management systems to identify gaps between current capabilities and AI requirements.
Resource planning involves calculating computational, storage, and networking needs for specific AI applications. Training large language models requires different infrastructure than deploying computer vision systems or running real-time recommendation engines for retail AI applications.
Skills assessment reviews the technical capabilities of current staff. AI infrastructure requires expertise in machine learning engineering, data engineering, infrastructure management, and security specialization.
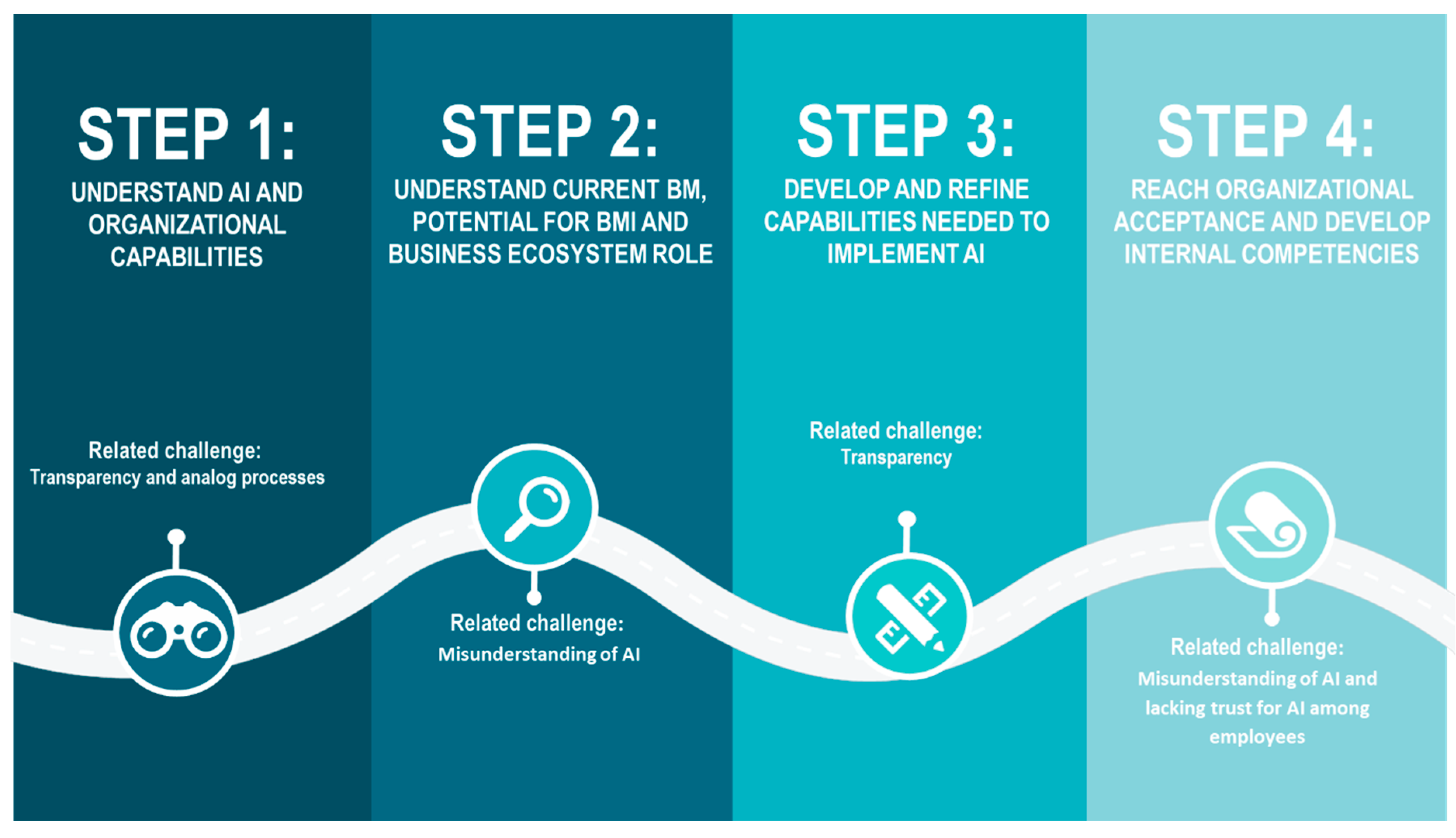
Phased Implementation Approach
Source: MDPI
Most organizations benefit from starting with pilot projects using cloud-based AI services before investing in dedicated infrastructure. This approach allows teams to understand AI requirements and develop expertise before committing to larger investments.
Proof-of-concept development validates AI approaches using minimal infrastructure investments. Teams can test technologies and measure performance before scaling to production systems. Organizations might start with simple implementations like AI chatbots before moving to more complex applications.
Infrastructure scaling follows successful pilots by gradually adding computational resources, storage capacity, and networking capabilities based on actual usage patterns and performance requirements.
Integration Considerations
Legacy system compatibility requires careful analysis of existing applications that must continue operating during AI infrastructure deployment. Organizations map data flows between current systems and planned AI components to identify integration points.
API development creates standardized interfaces allowing AI systems to communicate with existing applications. These interfaces handle data exchange and return AI results without disrupting normal business operations.
Security integration extends existing security protocols to cover AI infrastructure components while maintaining compatibility with current security frameworks.
Cost Management and Optimization
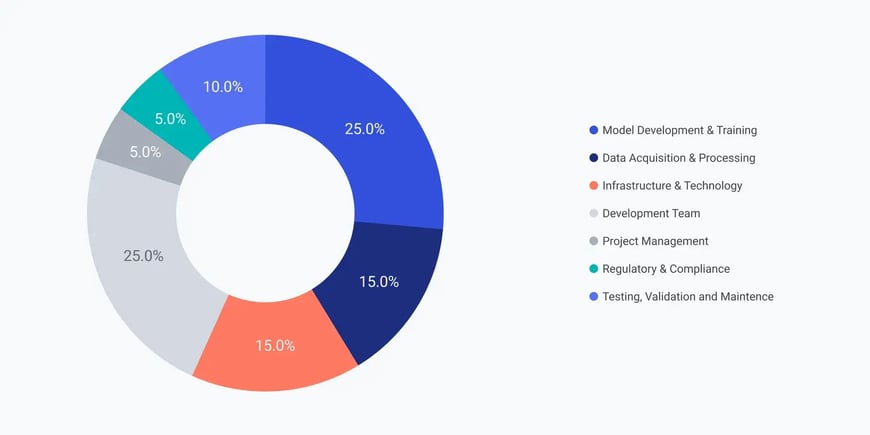
Source: Coherent Solutions
AI infrastructure costs include hardware expenses, software licensing, cloud computing resources, data storage, and operational expenses like electricity and cooling. Organizations often underestimate total ownership costs, leading to budget overruns.
Hardware costs vary significantly based on requirements. High-end GPUs can cost tens of thousands of dollars each, while complete AI training clusters may require hundreds of thousands or millions in investment.
Cloud costs depend on usage patterns. Training workloads typically generate higher expenses than inference operations due to their intensive computational requirements and longer duration.
Performance monitoring tracks resource utilization, application performance, and cost efficiency. Organizations establish metrics for GPU utilization, training time, inference latency, and cost per prediction to optimize their infrastructure investment.
Security and Compliance Requirements

Source: Mindgard
AI infrastructure creates new security challenges beyond traditional IT systems. Attackers can target AI systems through data poisoning, model extraction attacks, or adversarial inputs designed to manipulate AI outputs.
Data protection requires encryption at rest, in transit, and during processing. Privacy-preserving techniques like differential privacy and federated learning enable AI development while protecting sensitive information.
Regulatory compliance affects AI systems processing personal data, financial information, or operating in regulated industries. GDPR, HIPAA, and industry-specific regulations create requirements for data handling, model explainability, and audit trails.
Access control systems ensure only authorized personnel can access AI infrastructure components. Role-based permissions restrict access based on job functions, while monitoring systems track all infrastructure access and modifications.
Common Implementation Challenges
Data integration represents a primary obstacle as organizations struggle to connect information from multiple sources with different formats and quality levels. Legacy systems often lack the APIs needed to work seamlessly with modern AI platforms.
Skills gaps create significant challenges since many organizations lack personnel with expertise in both AI technologies and infrastructure management. The specialized nature of AI infrastructure requires training existing staff or hiring new team members with relevant experience.
Performance bottlenecks emerge when existing networking or storage infrastructure can’t handle AI workload requirements. Organizations may discover that their current systems lack the bandwidth, storage speed, or processing power necessary for AI applications.
Coordination between teams becomes complex as AI infrastructure projects require collaboration between data scientists, IT infrastructure specialists, security teams, and business stakeholders who may have different priorities and technical backgrounds.
Frequently Asked Questions About AI Infrastructure
What hardware do we need to start running AI models in our organization?
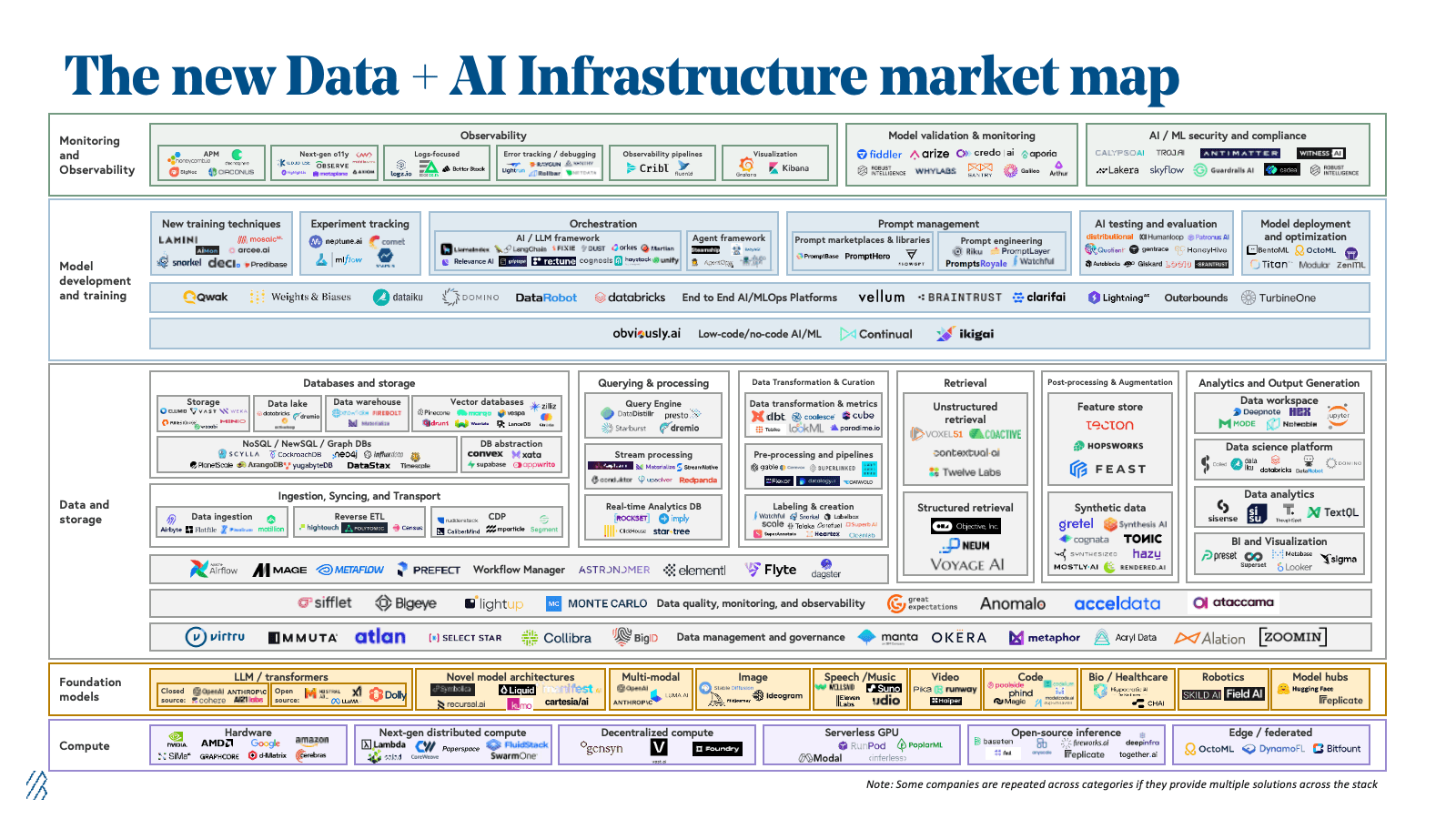
Source: Bessemer Venture Partners
The hardware requirements depend on your specific AI applications and scale. For basic machine learning tasks, modern servers with sufficient RAM and CPU power can handle smaller models. However, training neural networks or running complex AI models requires specialized graphics processing units (GPUs). Entry-level AI hardware might include servers with one or two GPUs like NVIDIA’s A100 or H100 series. Organizations processing large datasets or training complex models need multiple GPUs, high-speed storage systems, and substantial memory capacity. Cloud platforms offer an alternative for testing AI capabilities before investing in physical hardware.
How much does it typically cost to build AI infrastructure for a mid-size company?
AI infrastructure costs vary widely based on requirements and deployment approach. Cloud-based solutions can start at a few thousand dollars monthly for basic AI workloads, scaling up based on usage. On-premises infrastructure requires larger upfront investments, with basic AI-capable servers starting around $50,000 to $100,000. Complete enterprise AI infrastructure can range from hundreds of thousands to millions of dollars, including specialized processors, storage systems, networking equipment, and software licensing. Organizations should factor in ongoing costs for electricity, cooling, maintenance, and staff training when budgeting for AI infrastructure.
Can our existing IT team manage AI infrastructure, or do we need specialized personnel?
Existing IT teams can learn to manage AI infrastructure, but they’ll need additional training in machine learning operations, specialized hardware management, and AI-specific software platforms. AI infrastructure requires understanding of GPU management, machine learning frameworks like TensorFlow and PyTorch, container orchestration, and data pipeline management. Many organizations start by training current staff while gradually hiring specialists in machine learning engineering and AI operations. The complexity of AI workloads often justifies dedicated personnel who can optimize performance and troubleshoot AI-specific issues.
What’s the difference between using cloud AI services versus building our own infrastructure?
Cloud AI services provide immediate access to advanced capabilities without infrastructure investment. Platforms like AWS, Google Cloud, and Microsoft Azure offer managed AI services, pre-trained models, and scalable computing resources. This approach works well for experimenting with AI or handling variable workloads. Building your own infrastructure provides complete control over data, security, and system configuration. On-premises infrastructure suits organizations with consistent workloads, regulatory requirements, or sensitive data that can’t leave their environment. Many organizations use hybrid approaches, combining cloud services for development and experimentation with on-premises infrastructure for production workloads.
How do we ensure our AI infrastructure can scale as our needs grow?
Scalable AI infrastructure starts with choosing flexible platforms that accommodate growing data volumes and increasing model complexity. Container orchestration technologies like Kubernetes enable automatic scaling based on demand. Cloud platforms provide elastic resources that expand and contract based on usage patterns. Design data architectures that handle exponentially growing datasets without performance degradation. Microservices architectures allow individual components to scale independently. Monitoring tools track resource utilization to identify scaling needs before they impact operations. Planning for scalability includes selecting vendors and technologies that support growth without requiring complete infrastructure replacement.

