Adversarial AI refers to techniques that manipulate artificial intelligence systems to make incorrect decisions or produce harmful outputs. These attacks exploit how machine learning models process information, causing them to behave unexpectedly when given specially crafted inputs. Unlike traditional cyberattacks that target software bugs, adversarial AI attacks the fundamental way AI systems learn and make predictions.
The threat landscape has evolved dramatically since early research began. What started as academic experiments has become a practical security concern affecting everything from fraud detection systems to autonomous vehicles. Organizations now face sophisticated attackers who can fool AI systems while leaving no obvious trace of manipulation.
The scale of the problem has grown alongside AI adoption across industries. Financial institutions report that adversarial attacks now represent a significant portion of attempts to bypass their fraud detection systems. Healthcare organizations worry about manipulated medical images that could lead to misdiagnosis.
Types of Adversarial AI Attacks
Source: ResearchGate
Understanding the different types of adversarial attacks helps organizations recognize vulnerabilities and implement appropriate defenses. These attacks target different stages of the AI lifecycle and use various methods to compromise system behavior.
Evasion Attacks
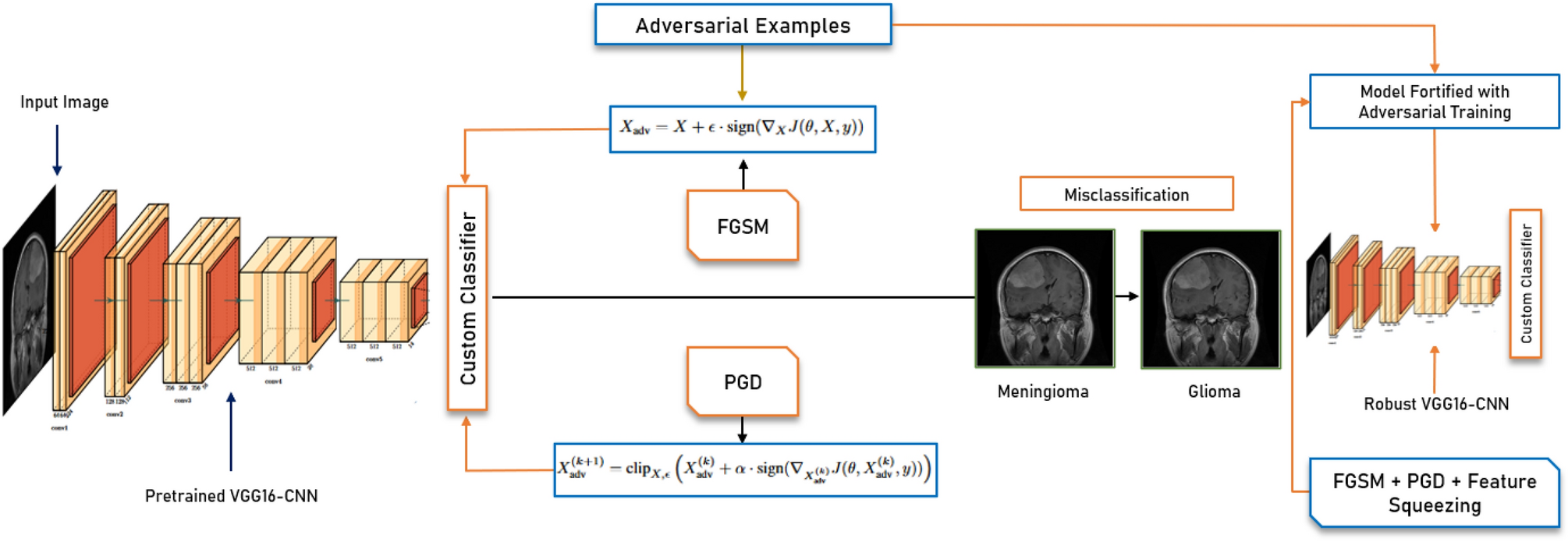
Evasion attacks represent the most common form of adversarial manipulation. Attackers modify input data during system operation to trick already-trained models into making wrong decisions. These attacks target deployed AI systems without changing the underlying training process.
Cybersecurity applications face frequent evasion attempts where attackers modify malicious network traffic to bypass AI-powered intrusion detection systems. The modifications appear harmless to human analysts but fool automated systems into classifying dangerous activity as benign.
Data Poisoning Attacks
Data poisoning attacks occur during the training phase of machine learning development. Malicious actors inject corrupted examples into training datasets, causing models to learn incorrect patterns. The poisoned behavior often remains hidden until specific trigger conditions activate the malicious functionality.
Large language models and other generative systems often train on vast collections of internet content that may include strategically placed malicious examples. These examples influence model behavior in subtle but significant ways that emerge during real-world use.
Model Extraction Attacks
Model extraction attacks involve systematic probing of AI systems to steal their functionality or training data. Attackers send carefully designed queries to understand how models make decisions. AI-as-a-service platforms have become frequent targets for these extraction attempts.
Privacy-focused extraction attacks aim to recover sensitive training data by exploiting how AI models sometimes memorize and reveal confidential information during inference. Organizations with proprietary AI systems face risks of intellectual property theft through these techniques.
Prompt Injection Attacks
Prompt injection attacks specifically target large language models and generative AI systems. Attackers craft special text inputs that override the model’s intended behavior or safety mechanisms. The OWASP GenAI project identifies prompt injection as the top risk facing generative AI deployments.
Multi-modal injection attacks exploit advanced AI systems that process multiple input types simultaneously, such as text and images. Attackers embed malicious prompts within images that accompany benign text, causing unexpected system behavior.
How Adversarial AI Attacks Work

Source: ResearchGate
Adversarial attacks exploit the mathematical foundations of how neural networks process information. Machine learning models create complex decision boundaries in high-dimensional spaces to classify inputs. Small, targeted changes to input data can push examples across these boundaries without human detection.
The National Institute explains that adversarial examples appear normal to human observers while causing machine learning models to make incorrect predictions. Attackers identify vulnerable spots in the model’s decision-making process and craft inputs that exploit these weaknesses.
Transfer attacks demonstrate that adversarial examples often work across different AI models trained on similar data. Attackers can develop techniques against accessible models and apply them to target systems they can’t directly access. This transferability significantly amplifies the threat potential.
Physical adversarial attacks manipulate real-world objects to fool computer vision systems. Researchers have shown that strategically placed stickers or lighting changes can cause autonomous vehicles to misread traffic signs. These physical modifications persist across different viewing angles and conditions.
Real-World Impact and Examples

Source: Consultancy.uk
Financial services institutions have become primary targets for adversarial manipulation of fraud detection systems. Attackers develop transaction patterns that appear legitimate to AI models while facilitating unauthorized activities. The sophisticated nature of these attacks often bypasses traditional security measures designed for human-generated fraud.
Tesla’s autopilot system demonstrated vulnerability to adversarial manipulation when researchers at McAfee showed that small modifications to speed limit signs could cause the vehicle to misread posted limits. These findings highlighted safety risks in AI-powered transportation systems where incorrect decisions could endanger lives.
Healthcare AI systems face threats from adversarial attacks on medical imaging and diagnostic tools. Subtle modifications to medical images can cause AI diagnostic systems to produce false positives or miss critical conditions that human medical professionals would easily identify. The high-stakes nature of medical decisions amplifies the potential impact of successful attacks.
Government and defense applications have experienced adversarial attacks from nation-state actors using synthetic content for influence operations. The Department of Homeland Security has documented cases where foreign adversaries used generative AI to create fake social media personas for political manipulation campaigns.
Defense Strategies Against Adversarial AI
Source: Nature
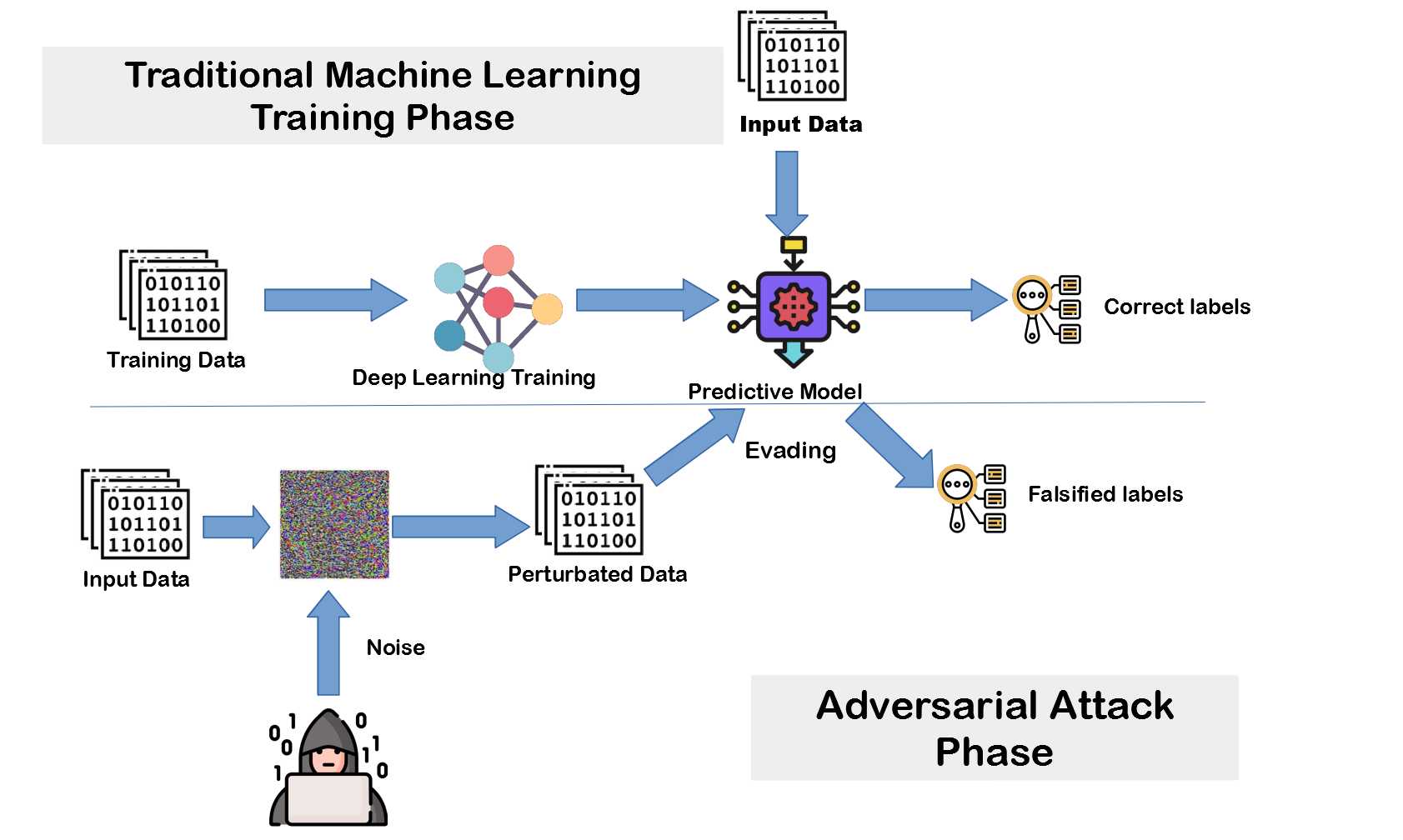
Organizations protect their AI systems through multiple defense strategies that work together to create layered security. Research shows that combining different protection methods produces better results than relying on any single approach. When implementing AI infrastructure, these defense considerations must be integrated from the ground up.
Adversarial Training Methods
Source: Medium
Adversarial training improves model robustness by including malicious examples during the development process. Models exposed to adversarial inputs during training learn to recognize and correctly classify manipulated data in production environments. This proactive approach helps systems resist future attack attempts.
Training datasets require careful balance between adversarial and legitimate examples. Research indicates that optimal ratios typically include 10 to 30 percent adversarial examples in training datasets, depending on the specific application and threat model.
Input Validation and Transformation Techniques
Input validation and transformation techniques serve as the first defense against adversarial manipulation. These methods detect and neutralize malicious inputs before they reach the AI model:
- Noise filtering — removes small-scale modifications that attackers typically use in adversarial examples
- Statistical analysis — identifies inputs that fall outside normal data distributions learned during training
- Format validation — ensures inputs match expected structures and constraints for specific applications
- Content sanitization — removes hidden prompt injection attempts from text inputs
Ensemble Methods
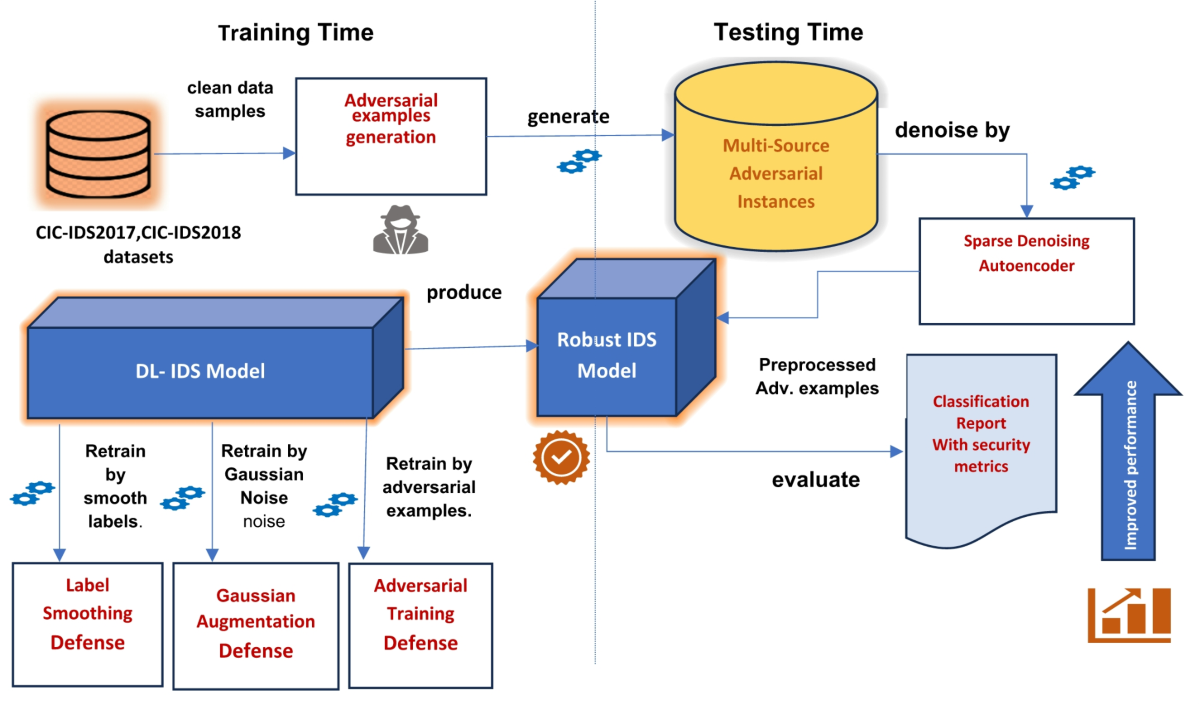
Source: Nature
Ensemble methods combine predictions from multiple models to make final decisions. Successful manipulation requires compromising several models simultaneously rather than just one. Research shows that attacks crafted against individual models often fail when applied to diverse ensemble configurations.
Effective ensembles use models with different architectures, training procedures, or data preprocessing steps. This diversity makes it much harder for attackers to find universal vulnerabilities that work across all models in the ensemble.
Continuous Monitoring Systems
Continuous monitoring systems track model inputs and outputs in real-time to identify suspicious patterns. Advanced monitoring analyzes multiple signals including input characteristics, output confidence levels, and behavioral patterns:
- Performance tracking — monitors accuracy and confidence metrics over time to detect degradation
- Behavioral analysis — identifies unusual patterns in model predictions or decision-making
- Anomaly detection — flags inputs that deviate significantly from expected data distributions
- Red team testing — involves dedicated security teams using adversarial techniques to identify vulnerabilities
Current Threat Landscape and Regulations

Source: Deepak Gupta
The United States Congress introduced the No Adversarial AI Act in 2025 to address threats from foreign adversary AI systems in government applications. The legislation mandates comprehensive lists of risky AI systems and establishes procedures for excluding these technologies from federal procurement processes.
The National Institute has published comprehensive taxonomies that standardize terminology and mitigation approaches across the adversarial AI field. The NIST AI Risk Management Framework includes specific guidance for systematic testing of AI systems to identify vulnerabilities before deployment. Organizations implementing responsible AI practices must consider these guidelines.
International coordination efforts have intensified as governments recognize that adversarial AI threats cross national boundaries. The Monetary Authority of Singapore has published detailed guidance on cyber risks associated with generative AI and deepfakes for financial institutions.
Industry-specific regulatory requirements have emerged across multiple sectors as authorities recognize domain-specific risks. Healthcare regulators are developing specialized frameworks for AI diagnostic systems that include adversarial robustness testing requirements. Aviation authorities are establishing certification requirements for safety-critical AI applications.
Building Adversarial AI Resilience
Organizations building effective adversarial AI defenses recognize that these threats represent a fundamental paradigm shift requiring specialized approaches beyond traditional cybersecurity measures. The complexity of adversarial threats demands understanding across multiple dimensions of AI system development and deployment.
Data poisoning attacks corrupt models during training, while evasion attacks manipulate deployed systems through carefully crafted inputs. Model extraction techniques enable attackers to steal proprietary AI capabilities, and prompt injection attacks compromise generative AI systems through malicious instructions.
Risk Assessment and Vulnerability Testing
Source: Generative AI
Vulnerability assessment begins with cataloging all AI applications, including those embedded in third-party software or cloud services. Each system receives classification based on its criticality to business operations and the potential impact of incorrect decisions.
Organizations examine their data collection processes, storage security, and validation procedures to identify points where adversaries could inject corrupted information. Training data sourced from public repositories or third-party providers carries higher risk due to limited quality control.
Evasion attack testing involves deliberately creating adversarial examples to probe model weaknesses during deployment. Security teams generate inputs designed to fool the AI system while appearing normal to human observers.
Vendor Evaluation Considerations
Vendor security assessment requires specific questions addressing adversarial AI threats beyond standard cybersecurity evaluations. Organizations examine vendor practices for adversarial training, where models learn to recognize and resist malicious inputs during development.
Training data provenance documentation reveals the sources and validation procedures for datasets used in model development. Vendors provide detailed information about data collection methods, quality control processes, and measures to prevent poisoning attacks.
Model robustness testing documentation shows systematic evaluation against adversarial attacks during development. Organizations examine whether vendors conduct both white-box testing with full model access and black-box testing simulating real-world attack conditions.
Frequently Asked Questions About Adversarial AI

Source: ResearchGate
What’s the difference between adversarial AI and traditional cybersecurity threats?
Traditional cybersecurity threats target known software vulnerabilities, system infrastructure, or human error to gain unauthorized access. Adversarial AI attacks focus specifically on manipulating the decision-making processes of machine learning systems rather than compromising underlying infrastructure. These attacks exploit the statistical, data-driven nature of AI models that make probabilistic decisions based on learned patterns.
How effective are adversarial attacks against production AI systems?
Current research shows that adversarial attacks can achieve success rates above 80 percent against certain production AI systems under controlled conditions. The effectiveness varies significantly based on the attack method, target system architecture, and defensive measures in place. Transfer attacks, where adversarial examples work across different AI models, demonstrate particular effectiveness in real-world scenarios.
Can organizations detect adversarial attacks in real-time?
Specialized AI security tools can detect many adversarial attacks by monitoring model behavior, input characteristics, and output confidence levels. These tools analyze multiple signals simultaneously, including unexpected prediction changes and input anomalies. However, sophisticated attacks designed to evade detection may require advanced monitoring systems and human expertise to identify.
What compliance requirements exist for adversarial AI security?
The EU AI Act requires comprehensive risk assessment and testing for high-risk AI applications. The NIST AI Risk Management Framework provides guidelines for systematic adversarial testing. Financial services face additional requirements under regulations like the Federal Reserve’s model risk management guidance that includes adversarial robustness considerations.
How much do adversarial AI defenses typically cost organizations?
Source: MDPI
Defense costs vary significantly based on system complexity and required security level. Organizations report that adversarial training can increase machine learning infrastructure costs by 30 to 80 percent due to extended training times and additional data processing requirements. Basic input validation and monitoring systems typically require annual investments between $50,000 to $200,000 for medium-sized deployments.
The path forward for organizations requires acknowledgment that adversarial AI security can’t be treated as an afterthought. Evidence from 2025 demonstrates that these threats have materialized into practical challenges requiring immediate attention and sustained investment. Organizations that implement comprehensive adversarial AI defenses position themselves to harness AI’s potential while protecting against evolving security threats.

