
AI privacy issues arise when artificial intelligence systems collect, process, or reveal personal data in ways that violate individual privacy rights or expectations.
The widespread adoption of AI across industries has created new privacy challenges that traditional data protection methods struggle to address. AI systems require massive amounts of data for training, often collecting personal information from millions of users without clear consent mechanisms. Machine learning models can inadvertently memorize and later reveal sensitive information from their training data, creating risks that persist long after the initial data collection.
These privacy concerns extend beyond simple data collection to include sophisticated new forms of surveillance, algorithmic bias, and synthetic content generation. Organizations implementing AI face complex compliance requirements as regulators worldwide develop new frameworks to address these emerging risks. The scale and sophistication of modern AI systems have outpaced existing privacy protection mechanisms, creating gaps in individual rights and organizational accountability.
Understanding AI Privacy and Why It Matters
AI privacy refers to protecting personal data within artificial intelligence systems throughout their entire lifecycle. This includes safeguarding information during data collection, model training, deployment, and ongoing operations.
Unlike traditional software that processes data in predictable workflows, AI systems analyze vast datasets to identify patterns and make inferences. These systems can reveal sensitive information about individuals even when that wasn’t the original purpose. Machine learning models sometimes memorize personal data from training sets, creating privacy risks that continue long after deployment.
The privacy challenges differ from conventional software because AI can generate new insights about people by combining seemingly harmless data points. A shopping recommendation system might reveal someone’s health condition by analyzing their purchase patterns, or a facial recognition system might track someone’s daily routine across multiple locations.
How AI Systems Collect Personal Data
AI systems consume enormous amounts of data to function effectively, creating privacy challenges unlike previous technologies. Modern language models train on datasets containing text from billions of web pages, while image recognition systems analyze millions of photographs that may contain private information.
Common Data Collection Methods
AI developers gather training data through several primary approaches:
- Web scraping operations — automated programs systematically download content from websites, forums, and platforms, often capturing personal information shared in comments and posts
- Social media platforms — users share personal experiences, photos, and opinions that become part of training datasets without explicit consent
- Commercial data purchases — organizations buy datasets from data brokers who compile information from public records and online behavior tracking
- Government records — court documents, property records, and regulatory filings containing names, addresses, and personal details

Source: Velaro
Healthcare organizations might collect patient images for treatment, then later use those same images to train commercial AI systems. E-commerce companies analyze purchase histories to build recommendation engines that can infer personal preferences and financial situations.
Real-Time Processing Concerns
Beyond initial training data, AI systems continuously process new information during operation. Search engines record queries and click patterns, recommendation systems track viewing habits, and voice assistants capture speech patterns during conversations.
Mobile applications with AI features collect location data, device usage patterns, and interaction timestamps that reveal daily routines. These systems build comprehensive profiles that extend far beyond individual interactions, tracking behavior patterns across multiple sessions and platforms.
Data Security Vulnerabilities in AI
AI systems create concentrated, high-value targets for cybercriminals seeking personal information or intellectual property. A single AI training dataset can contain millions of records spanning customer information, financial data, and personal communications.
Model Extraction Attacks
Cybercriminals can steal AI models by repeatedly querying target systems and analyzing responses. Attackers send carefully crafted inputs and study outputs to reverse-engineer the underlying model architecture and training data.
Once extracted, stolen models reveal proprietary algorithms, training data patterns, and potentially sensitive information about individuals whose data was used during training. Organizations with public APIs face particular vulnerability since attackers can use automated tools to rapidly query models at scale.
Data Poisoning Risks
Malicious actors deliberately corrupt training datasets to compromise AI system integrity. Attackers inject false or misleading data into training sets to manipulate how models learn and make decisions.
These attacks can occur during initial data collection or through ongoing data updates. The poisoned data becomes embedded in the model’s decision-making logic, causing incorrect outputs or biased behavior that can be difficult to detect.
AI Surveillance and Privacy Erosion
AI-powered surveillance creates unprecedented capabilities for systematic monitoring of human behavior. These systems can track individuals continuously across multiple environments, processing vast amounts of data to identify patterns and predict actions.
Facial Recognition Technology
Facial recognition systems analyze facial features to identify specific individuals from images or video streams. Modern AI can process this data in real-time, comparing faces against databases containing millions of stored images with accuracy rates above 95 percent under optimal conditions.

Source: ResearchGate
Cameras equipped with facial recognition software track individuals as they move through retail stores, transportation hubs, and public streets. Each identification creates a data point contributing to comprehensive records of someone’s movements and activities.
Private spaces increasingly use facial recognition for access control and security. Office buildings grant employee access while retail establishments identify known shoplifters or VIP customers, expanding potential identification into environments where people previously expected greater privacy.
Location Tracking Capabilities
AI-powered location tracking combines data from GPS satellites, WiFi networks, cellular towers, and Bluetooth beacons to determine precise geographic positions. Smartphones and connected devices continuously transmit location data, creating detailed movement records throughout the day.
WiFi-based tracking operates independently of GPS by detecting device connections to wireless networks. Retail stores and shopping centers use WiFi tracking to monitor customer movements and measure time spent in specific areas.
Algorithmic Bias and Discrimination
AI systems can perpetuate and amplify existing biases when they learn from data reflecting societal inequalities. Unlike human bias, which might be inconsistent, algorithmic bias operates at scale with mathematical precision, making the same biased decisions thousands or millions of times.
Training Data Bias
Historical data often contains centuries of societal biases that AI systems learn as normal patterns. When organizations train models on hiring practices, loan approvals, or criminal justice decisions from the past, AI learns to replicate discriminatory decision-making.

Source: Hacking HR
For example, if historical hiring data shows companies primarily hired men for engineering positions, an AI system trained on this data will learn that men are better candidates. The system interprets this pattern as legitimate qualification rather than recognizing past discrimination.
Medical AI systems trained primarily on data from white male patients may not accurately diagnose conditions in women or people of color. Facial recognition systems with limited racial diversity in training data perform poorly on people from underrepresented groups.
Automated Decision-Making Risks
AI systems make millions of automated decisions daily in employment, lending, healthcare, and criminal justice that directly impact people’s lives. When these systems contain bias, they can systematically exclude qualified candidates, deny loans to creditworthy applicants, or recommend different treatment based on demographic characteristics.
- Employment screening — AI might automatically reject resumes with foreign-sounding names or downgrade candidates from historically Black colleges
- Lending algorithms — systems might deny loans to people in certain zip codes based on demographic proxies rather than creditworthiness
- Healthcare AI — biased systems might provide different quality care recommendations based on patient race or gender
- Criminal justice — risk assessment tools have been criticized for incorrectly flagging Black defendants as high-risk at nearly twice the rate of white defendants
Consent and Transparency Challenges
AI systems create unique consent challenges that traditional software governance frameworks struggle to address. The consent challenge stems from AI’s complex processing methods where ultimate applications often remain unknown at data collection time.
Traditional vs. AI Consent Requirements
Traditional software operates with specific, defined use cases where users can make informed decisions about data sharing. AI systems often involve multi-stage processing where data collected for one purpose gets used for entirely different applications without additional consent.
AI decision-making transparency presents equally complex challenges. Many machine learning systems operate as “black boxes” where the decision-making process remains unclear even to developers. When an AI system denies a loan application, stakeholders often can’t explain the specific factors that influenced the decision.
Privacy policies fail to adequately explain complex AI processing, making it difficult for users to understand how their data will be used in machine learning applications. Organizations routinely repurpose existing data for AI training without seeking additional consent from original data subjects.
Privacy Regulations for AI Systems
Organizations deploying AI operate within complex privacy regulations that govern personal data collection, processing, and protection. These regulations create specific compliance obligations that extend beyond traditional data protection requirements.
GDPR and AI Compliance
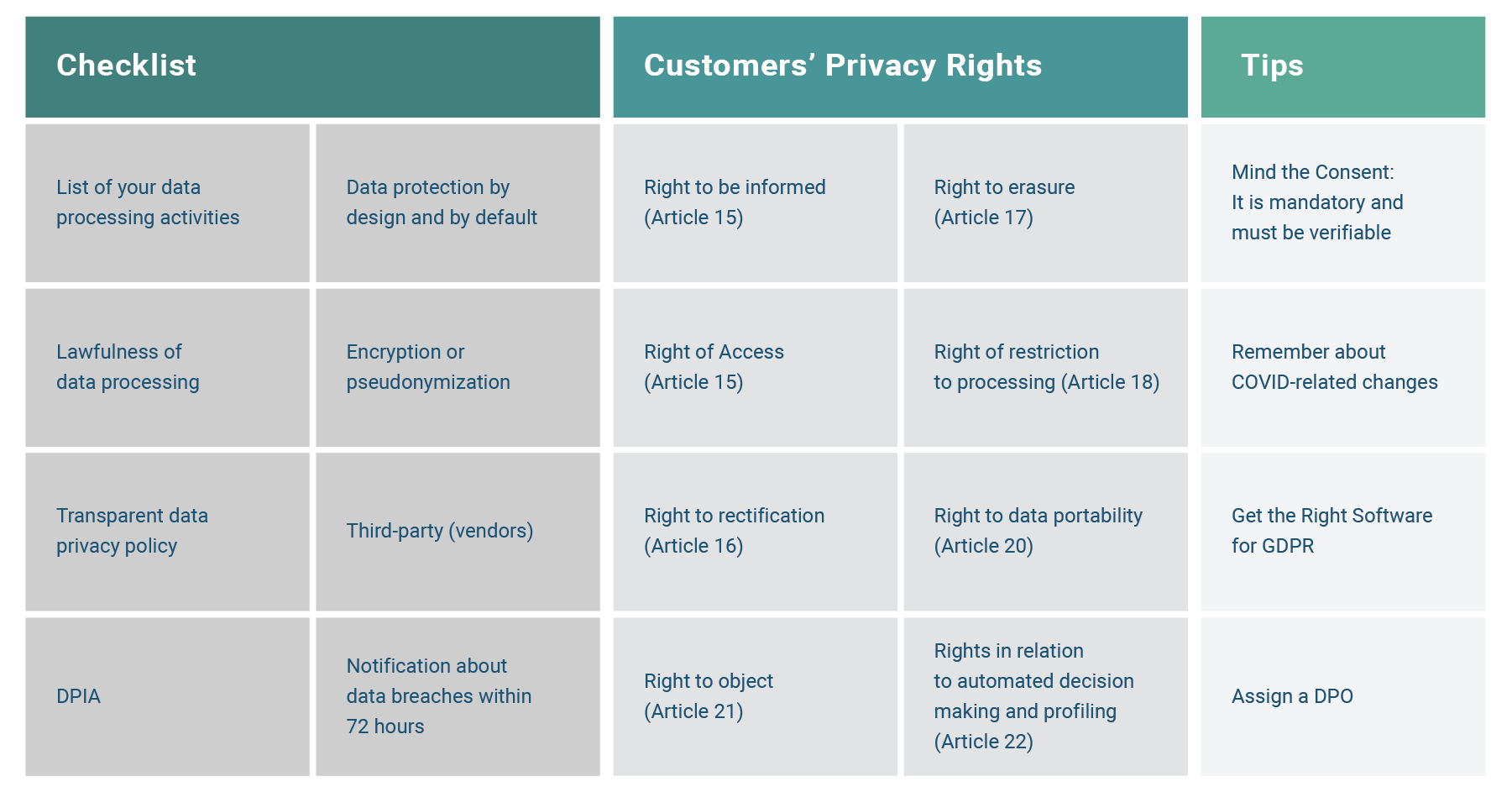
The General Data Protection Regulation establishes fundamental privacy rights that directly impact AI system development and deployment within the European Union. GDPR’s core principles of lawful basis, purpose limitation, and data minimization create specific constraints on AI training and operation.
Source: Compliance Aspekte
The right to explanation under GDPR requires organizations to provide meaningful information about automated decision-making. AI systems often lack transparency, so organizations implement explainable AI techniques and maintain detailed records of model training and deployment.
Data portability rights enable individuals to obtain their personal data in structured, machine-readable formats. For AI systems, this creates challenges in determining what constitutes personal data when information has been processed through machine learning algorithms.
The right to erasure requires organizations to delete personal data under specific circumstances. AI systems complicate erasure because personal information may be embedded within trained models in ways that make selective deletion technically challenging.
Emerging AI-Specific Laws
The European Union’s AI Act, which began implementation in 2024, establishes a comprehensive regulatory framework specifically targeting artificial intelligence systems. The Act categorizes AI systems by risk level and imposes corresponding obligations for transparency, accuracy, and human oversight.
Several U.S. states have enacted AI-specific privacy legislation beyond existing data protection laws. California’s proposed AI regulations would require impact assessments for high-risk systems and establish obligations for algorithmic transparency.
China has implemented regulations for algorithmic recommendations and generative AI services, requiring organizations to obtain consent for personalized recommendations and provide transparency about algorithmic decision-making.
Privacy-Preserving AI Implementation
Organizations can protect individual privacy while developing AI systems through structured approaches that address data collection, model training, and deployment phases. Effective privacy protection requires planning from the initial design phase rather than adding measures after development.
Privacy by Design Principles
Privacy by design embeds privacy protection directly into AI system architecture during initial development. This approach treats privacy as a core system requirement rather than an optional feature added later.
Development teams consider privacy implications when making technical decisions about data storage, processing methods, and model architecture. Technical implementation includes designing data pipelines that automatically delete unnecessary information and using encryption for data transmission and storage.
Data Minimization Techniques
Data minimization involves collecting only specific information required for particular AI functions rather than gathering comprehensive datasets. Organizations identify minimum data requirements for each AI use case and establish collection limits preventing unnecessary information gathering.
Practical approaches include setting collection timeframes that automatically delete old data, filtering datasets to remove irrelevant personal information, and using synthetic data generation for testing phases. Organizations establish data retention schedules specifying how long different information types can be stored.
Technical Privacy Safeguards
Technical safeguards use computational methods to protect individual identities while preserving data utility for AI training. These techniques transform datasets making it difficult to identify specific individuals while maintaining statistical properties needed for machine learning.
— Differential privacy — adds mathematical noise to datasets preventing identification of individual records while preserving statistical accuracy
— Federated learning — trains models across distributed data sources without centralizing sensitive information
— Homomorphic encryption — enables computation on encrypted data without decrypting it first
— k-anonymity — ensures each record is indistinguishable from at least k-1 other records

Source: ResearchGate
Organizations select methods based on specific privacy requirements, computational resources, and data sensitivity. Many implementations combine multiple techniques to create layered privacy protection addressing different risks while maintaining data quality needed for effective AI systems.
Building AI Privacy Governance
Source: Collibra
Creating effective AI privacy governance requires integrating technical safeguards, organizational policies, and compliance frameworks. Organizations must balance protecting personal data while enabling AI innovation through careful planning and ongoing management.
Privacy impact assessments evaluate potential risks before deploying AI systems. These assessments examine training data composition, model architecture choices, and potential privacy leakage scenarios. Organizations conduct assessments early in development cycles to identify and address privacy concerns before deployment.
Ongoing monitoring represents a critical component often overlooked in initial framework design. AI models can drift over time, potentially developing new privacy risks as they encounter different data patterns. Regular auditing processes examine model outputs for signs of privacy leakage using both automated tools and human review.
Access controls and data minimization principles guide how organizations limit exposure to sensitive information. Role-based access ensures only authorized personnel interact with personal data during AI development, while data minimization practices collect and retain only information necessary for specific AI objectives.
Organizations implementing responsible AI practices benefit from establishing comprehensive governance frameworks that address privacy alongside other ethical considerations. These frameworks help ensure AI systems serve customer needs while maintaining privacy protection standards.
Frequently Asked Questions About AI Privacy
What specific steps can small organizations take to implement AI privacy protection?
Small organizations can start with basic privacy measures including data encryption, access controls, and clear data retention policies. Implementing privacy by design principles during AI development planning costs significantly less than addressing privacy issues after deployment.
Organizations should conduct privacy impact assessments before deploying AI systems, even simple ones. These assessments help identify potential privacy risks early and guide implementation of appropriate safeguards. Many privacy-preserving techniques like data minimization and anonymization can be implemented without significant technical expertise.
How can organizations determine if their AI training data contains private information?
Organizations can audit training datasets by scanning for direct identifiers like names, addresses, and social security numbers. However, identifying indirect privacy risks requires analyzing whether combinations of seemingly harmless data points could reveal sensitive information about individuals.
Data auditing tools can automatically detect patterns that might lead to privacy violations. Organizations should also review data sources to understand collection methods and ensure appropriate consent was obtained. Regular audits help identify privacy risks as datasets grow and change over time.
What happens when AI models need to be retrained after privacy violations?
Model retraining after privacy violations often requires completely rebuilding AI systems using cleaned datasets. Organizations must remove problematic data from training sets and implement additional privacy safeguards before retraining begins.
The retraining process can take months and cost hundreds of thousands of dollars depending on model complexity. Organizations may also face regulatory requirements to notify affected individuals and implement enhanced monitoring procedures. Prevention through initial privacy protection proves far less expensive than post-violation remediation.
How do privacy requirements differ between AI used for internal operations versus customer-facing applications?
Internal AI applications still require privacy protection but may have more flexibility in implementation approaches. Organizations have greater control over internal data flows and can implement role-based access controls more easily than with external systems.
Customer-facing AI applications face stricter privacy requirements including explicit consent mechanisms, transparency obligations, and individual rights to access or delete personal data. These systems often require additional safeguards like differential privacy or federated learning to protect customer information while maintaining functionality.
What privacy considerations apply when using generative AI for content creation?
Generative AI systems can inadvertently reproduce personal information from their training data when creating new content. Organizations using these systems should implement output filtering to detect and remove potentially sensitive information before publication.
Training data for generative AI often includes copyrighted content, personal communications, and proprietary information without explicit consent. Organizations should review licensing agreements and implement attribution mechanisms when required. Regular monitoring helps identify when generated content might violate privacy rights or reproduce protected information.
Conclusion
AI privacy challenges require comprehensive approaches that address technical, organizational, and regulatory requirements. The complexity of AI systems creates privacy risks that extend far beyond traditional data protection, from model memorization of training data to sophisticated surveillance capabilities.
Organizations implementing AI must adopt privacy by design principles that integrate protection measures throughout development lifecycles. Technical safeguards like differential privacy and federated learning provide mathematical guarantees while governance frameworks ensure accountability and transparency in AI decision-making.
The regulatory landscape continues evolving as governments develop sophisticated approaches to AI governance. Organizations that proactively implement privacy protection measures will be better positioned to adapt to new requirements while maintaining competitive advantages. The investment in privacy-preserving AI technologies today significantly outweighs potential costs of regulatory violations and remediation efforts that may result from inadequate protection.

