Retrieval Augmented Generation (RAG) is an artificial intelligence framework that combines large language models with external knowledge databases to provide more accurate and current responses. RAG systems work by first searching relevant documents from a knowledge base, then using that information to generate answers grounded in factual data.

Source: IBM
Traditional AI chatbots rely only on information learned during training, which becomes outdated over time. RAG solves this problem by connecting AI models to live databases of current information. When someone asks a question, the system finds relevant documents and uses them as reference material for creating accurate responses.
Enterprise organizations increasingly adopt RAG systems to build AI applications that access proprietary company data while maintaining accuracy and reducing hallucinations. The technology enables AI assistants that can cite sources and provide verifiable answers based on authorized knowledge repositories.
How RAG Works in Three Simple Steps
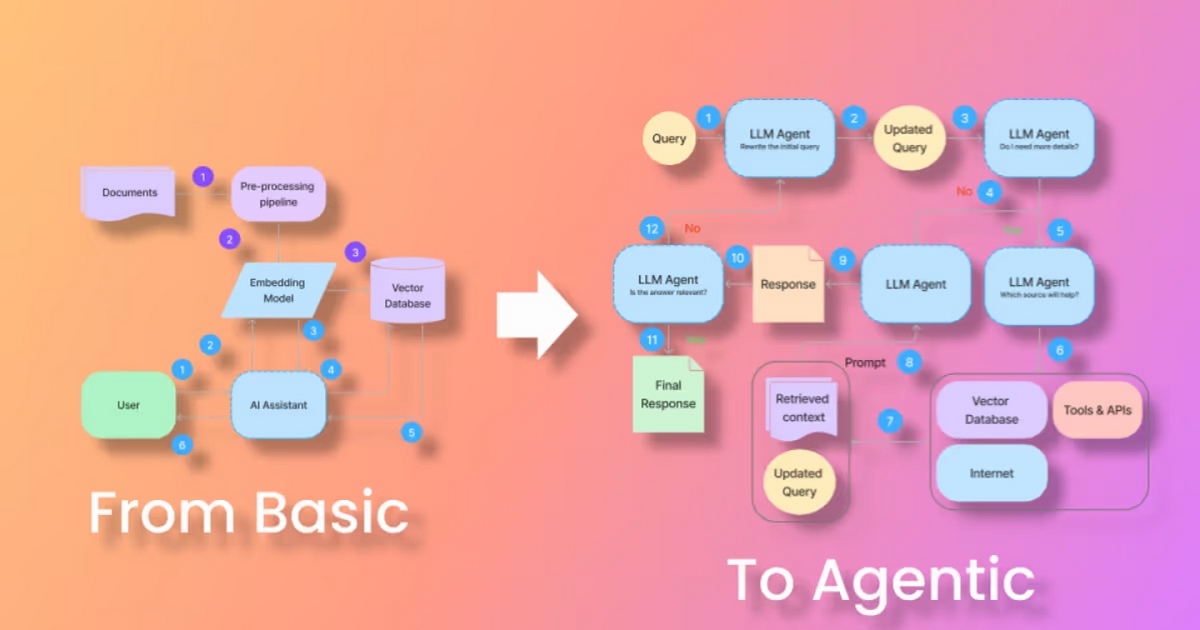
RAG systems operate through a straightforward three-step process. First, the system converts user queries into mathematical representations called embeddings that capture the meaning behind words. These embeddings help the system understand what you’re asking for, even if you phrase it differently than the information in the database.

Source: The Cloud Girl
The retrieval step searches through pre-indexed documents using vector databases. Instead of looking for exact word matches, the system finds information that’s conceptually similar to your question. When someone asks “How do I reset my password?”, the system might find documents about “account recovery” or “login troubleshooting.”
The generation step combines everything together:
- Context gathering — The system takes the most relevant documents it found
- Prompt construction — It combines your original question with the retrieved information
- Response creation — A language model uses both pieces to write a helpful answer
This process happens in seconds, giving you answers that are both conversational and backed by real information from the company’s knowledge base.
Why RAG Beats Traditional Language Models
Language models trained on static datasets can’t access information beyond their training cutoff dates. If a model was trained in 2023, it won’t know about events or changes from 2024. RAG addresses this limitation by connecting models to knowledge sources that organizations can update independently.

Source: Ankur’s Newsletter
RAG systems reduce hallucinations — those confident-sounding but incorrect answers that AI sometimes gives. Traditional language models generate responses based on statistical patterns, which can lead to plausible but wrong information. RAG systems retrieve actual documents first, so responses are grounded in verifiable source material.
Cost efficiency represents another major advantage:
- No retraining needed — Companies can update their knowledge without expensive model retraining
- Faster updates — New information becomes available immediately after adding it to the database
- Resource savings — Organizations avoid the computational costs of training new models
Common RAG Use Cases for Businesses
Customer service applications represent the most common RAG implementations. AI assistants can access product manuals, troubleshooting guides, and policy documents to provide instant, accurate support. Instead of transferring customers to human agents, these systems retrieve relevant information and provide step-by-step solutions.
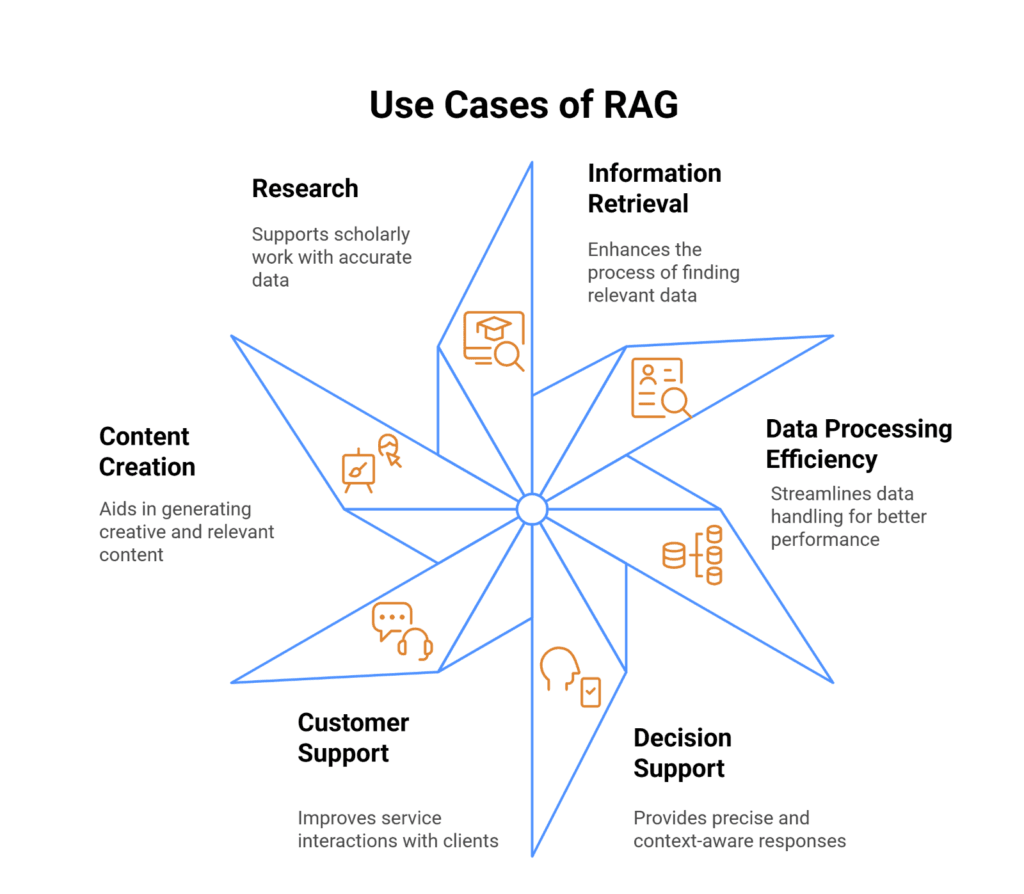
Source: Kanerika
Legal and compliance teams use RAG systems to navigate complex regulatory frameworks. These applications help professionals quickly locate relevant statutes, case law, and internal policies while providing citations for verification. The technology proves valuable for due diligence processes where accuracy and source attribution are critical.
Manufacturing organizations deploy RAG to help frontline workers access technical documentation. Workers can ask questions in everyday language and receive relevant information from equipment manuals, safety protocols, and troubleshooting guides without stopping to search through paper documents.
Building a RAG System — Key Components
RAG systems require vector databases to store and search document embeddings efficiently. These specialized databases enable rapid similarity searches across large document collections. Popular options include managed services like Pinecone or open-source solutions like FAISS and Milvus.

Source: Medium
Data preparation involves several important steps. Organizations must ingest documents from various sources, clean and structure the content, and convert text into embeddings using specialized models. The chunking strategy divides large documents into smaller segments that fit within language model limits while keeping related information together.
Integration components orchestrate the entire process:
- Query processing — Converting user questions into searchable formats
- Retrieval coordination — Managing searches across knowledge bases
- Prompt construction — Combining queries with retrieved information
- Response generation — Coordinating with language models to create answers
Common Challenges When Implementing RAG
Retrieval quality directly impacts how well the system performs. Poor search results provide inadequate context for accurate answers. Organizations must carefully tune embedding models, chunking strategies, and search parameters to ensure relevant information surfaces consistently. Many teams use hybrid search approaches that combine semantic similarity with traditional keyword matching.
Source: Label Studio
Data quality issues in knowledge bases can amplify problems in generated responses. If the source documents contain errors or outdated information, the RAG system will propagate these issues. Organizations need robust data governance processes to maintain knowledge base accuracy and currency.
Context window limitations constrain how much retrieved information language models can process effectively. Most models have limits on input length, so systems must balance providing comprehensive context against these capacity constraints. Advanced implementations use techniques like iterative retrieval and context compression to optimize information utilization.
Getting Started With RAG Implementation
Organizations typically begin by identifying specific use cases where current, accurate information access provides clear business value. Customer service, technical documentation, and compliance applications often represent strong starting points because they have measurable outcomes and clear success criteria.
Knowledge base preparation requires careful curation of authoritative sources. Teams must define data quality standards, implement access controls, and create workflows for maintaining currency. This preparation phase often takes longer than expected but determines the system’s overall effectiveness.
Technical implementation involves several key decisions:
- Vector database selection — Based on scalability needs and operational preferences
- Embedding model choice — Balancing accuracy with computational requirements
- Orchestration framework — Determining how components work together
Performance testing with realistic workloads helps identify bottlenecks before deployment. Companies should consider conducting an AI maturity assessment to evaluate their readiness for RAG implementation.
Measuring RAG System Performance
Establishing appropriate metrics represents a critical step for system optimization. Organizations track both technical performance indicators and business outcomes. Technical metrics include retrieval accuracy, response latency, and system uptime, while business metrics cover user satisfaction scores and operational cost reductions.
Source: ProjectManager
Regular monitoring enables identification of performance degradation patterns. These might indicate knowledge base staleness, retrieval mechanism drift, or changing user query patterns. Feedback loops allow continuous refinement of chunking strategies, prompt engineering, and retrieval algorithms based on observed system performance.
User feedback collection helps identify when the system provides unhelpful or inaccurate responses. Many organizations implement rating systems where users can quickly indicate whether responses were helpful, allowing teams to identify and fix problematic areas.
Advanced RAG Strategies and Future Considerations
As RAG systems mature within organizations, considerations shift toward scaling across additional use cases and integrating multiple knowledge sources. Advanced implementations may incorporate multiple retrieval strategies, specialized embedding models for different content types, and sophisticated orchestration mechanisms that adapt approaches based on query characteristics.
The evolution of underlying technologies requires ongoing evaluation and potential system updates. Improved embedding models, more efficient vector databases, and enhanced language models become available regularly. Organizations benefit from maintaining flexibility in their RAG architectures to accommodate technological advancement while preserving investments in data preparation.
Future RAG developments focus on:
- Multi-modal capabilities — Processing images, videos, and audio alongside text
- Real-time learning — Systems that improve from user interactions
- Enhanced reasoning — Better handling of complex, multi-step questions
RAG represents a practical approach for organizations seeking AI systems that provide accurate, verifiable responses while maintaining control over knowledge sources. The technology addresses fundamental limitations of traditional language models by enabling dynamic access to current information through structured retrieval processes. Success depends on careful attention to data quality, retrieval optimization, and ongoing system monitoring to ensure consistent performance and accuracy.

