Tensor Processing Units (TPUs) and Graphics Processing Units (GPUs) are specialized computer chips designed to accelerate artificial intelligence computations.
The rise of artificial intelligence has created an enormous demand for computational power. Traditional computer processors struggle with the massive parallel calculations required to train and run AI models. Modern neural networks contain billions of parameters that must be processed simultaneously, creating bottlenecks that can slow training from days to months.
Two types of specialized processors have emerged to solve this problem. GPUs originally designed for video games have been adapted for AI work due to their ability to handle thousands of calculations at once. TPUs represent a newer approach, built specifically for the mathematical operations that AI systems use most frequently.
What Are TPUs and GPUs in AI Computing
TPUs and GPUs are specialized computer processors designed to handle the massive computational requirements of artificial intelligence systems. While regular computer processors (CPUs) execute tasks one at a time, AI workloads require thousands of mathematical operations to happen simultaneously.
Graphics Processing Units (GPUs) originally powered video game graphics but evolved into AI workhorses due to their ability to perform many calculations at once. Tensor Processing Units (TPUs) represent Google’s custom-built chips designed exclusively for neural network operations.
Graphics Processing Units for Parallel AI Processing
Graphics Processing Units emerged from the video gaming industry in the 1990s, originally designed to render three-dimensional graphics for games and visual applications. Video game graphics require calculating the position, color, and lighting of thousands of pixels simultaneously — a task that demands parallel processing rather than the sequential processing that traditional CPUs provide.
GPUs contain thousands of small, efficient cores compared to CPUs, which typically have fewer than a dozen high-performance cores. Each GPU core handles simple mathematical operations, but when thousands of cores work together, they can process massive amounts of data simultaneously.
The breakthrough came in 2006 when NVIDIA introduced CUDA, a programming platform that allowed developers to use GPUs for tasks beyond graphics rendering. Machine learning researchers discovered that training neural networks involved the same type of parallel matrix calculations that GPUs performed for graphics.
Tensor Processing Units for Neural Network Operations
Tensor Processing Units are custom silicon chips that Google designed specifically for neural network computations. Google announced the first TPU in 2016, revealing that these processors had already been operating in Google’s data centers for over a year, powering services like search and translation.
TPUs focus on tensor operations — mathematical calculations involving multi-dimensional arrays of numbers that form the foundation of neural network processing. The name “tensor” refers to these mathematical structures that represent data flowing through neural networks.
The TPU architecture uses a systolic array design where data flows through processing units in a choreographed pattern. Each processing unit performs one operation and passes results to neighboring units, creating an efficient pipeline that maximizes computational throughput while minimizing power consumption.
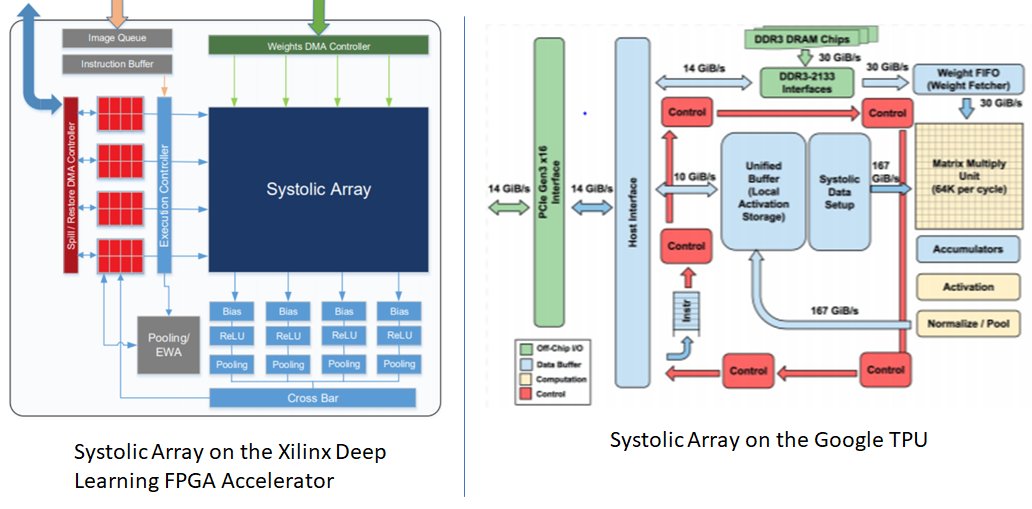
Source: Telesens
Architecture Differences Between TPUs and GPUs
TPUs and GPUs approach AI computation through fundamentally different hardware designs. GPUs evolved from graphics processors and contain thousands of small, efficient cores optimized for parallel processing. Modern data center GPUs typically feature 2,500 to 5,000 CUDA cores alongside specialized tensor cores.
TPUs prioritize tensor operations through systolic arrays rather than general-purpose cores. The first-generation TPU employed a systolic array containing 65,536 arithmetic logic units in a 256 × 256 configuration. Cloud TPU v3 features two systolic arrays of 128 × 128 arithmetic logic units on a single processor.
Parallel Processing Methodologies
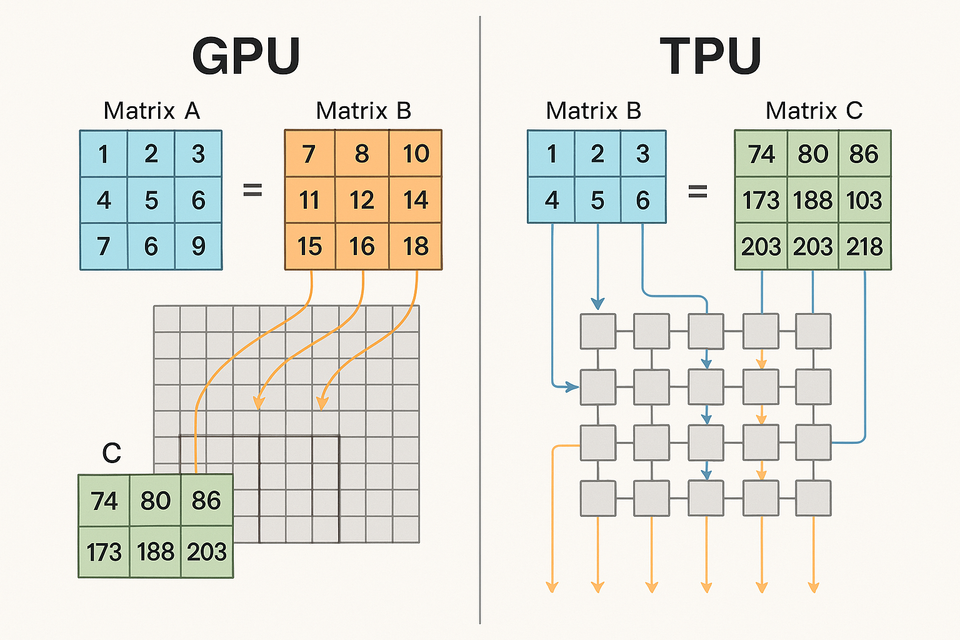
GPUs employ Single Instruction Multiple Thread (SIMT) execution where multiple cores execute the same instruction across different pieces of data concurrently. This approach means one instruction gets broadcasted to many processing units, which then perform the same operation on different data points simultaneously.
TPUs utilize systolic array architectures where data flows through computational units in highly orchestrated waves. In a systolic array, each arithmetic unit performs a single operation and passes results directly to neighboring units without requiring memory access for intermediate values.
The systolic array design creates a pipeline that maximizes computational unit utilization. Data enters the array at one edge, flows through multiple processing elements, and exits at the opposite edge after undergoing multiple transformations.
Memory Systems and Bandwidth Capabilities
GPU memory hierarchies prioritize low-latency operations to maintain consistent performance across graphics and general computing workloads. Modern AI-focused GPUs utilize high bandwidth memory technologies like HBM2 and HBM3. NVIDIA’s H100 Tensor Core GPU features 80 GB of HBM3 memory delivering up to 3.35 TB/s of memory bandwidth.
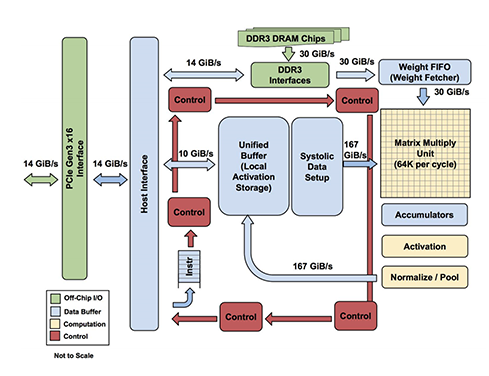
TPU memory architectures optimize for bandwidth rather than latency, typically offering improved energy efficiency compared to GPU memory systems. TPUs feature large unified buffers that serve as high-speed on-chip memory, reducing expensive off-chip memory accesses that consume substantial power.
Data access patterns reveal fundamental architectural differences. GPUs support random memory access patterns required by diverse applications. TPUs optimize for sequential and predictable access patterns common in neural network operations.
Performance Benchmarks for AI Workloads
Modern AI systems require processors that can handle thousands of calculations simultaneously while moving massive amounts of data efficiently. TPUs use specialized circuits called systolic arrays that excel at the matrix multiplications common in neural networks. GPUs leverage thousands of smaller cores that can work in parallel across diverse computational tasks.
Training Speed Comparisons
Training an AI model involves feeding it examples repeatedly until it learns to recognize patterns. The process requires enormous computational resources, with some models taking weeks or months to complete training on traditional hardware.

Source: Google Cloud
TPUs demonstrate substantial advantages for training models that rely heavily on standard neural network operations. Research workloads that typically require several weeks on GPU clusters often complete in less than half that time on TPU systems.
GPU performance varies significantly based on the specific model architecture and software framework. Models with complex control flow or custom operations often run more efficiently on GPUs due to their flexible instruction sets.
Inference Latency and Throughput Metrics
Inference refers to using a trained AI model to make predictions on new data, while training involves teaching the model from examples. Inference typically requires less computational power than training but demands consistently low response times for real-world applications.
TPUs achieve notably faster inference for models built around transformer architectures, which form the backbone of modern language models. The specialized tensor operations complete common inference calculations in fewer clock cycles compared to general-purpose GPU architectures.
GPU inference performance depends heavily on optimization techniques and batch processing strategies. Single requests often complete faster on TPUs, but GPUs can achieve higher total throughput when processing multiple requests simultaneously.
Cost Comparison and Total Ownership Analysis
Understanding the true cost of AI hardware requires looking beyond initial purchase prices or hourly cloud rates. Total cost of ownership includes hardware acquisition, operational expenses, personnel training, software licensing, and infrastructure requirements over multiple years.
Cloud Pricing Models and Hardware Costs
GPU cloud pricing varies across providers with consistent market competition. NVIDIA Tesla V100 instances cost approximately $2.48 per hour, while A100 instances run around $2.93 per hour across major cloud platforms.
TPU pricing operates exclusively through Google Cloud Platform. TPU v3 instances cost approximately $4.50 per hour, while TPU v4 runs about $8.00 per hour. Google does not sell TPU hardware directly, limiting deployment options to cloud-only arrangements.
Hourly rates alone provide incomplete cost comparisons. Training requiring 7-10 days on eight A100 GPUs might complete in 3-4 days on TPU v4 pods, effectively reducing total computational costs by 50-60 percent for compatible workloads.
Operational Expenses and Power Consumption
Operational expenditure encompasses ongoing costs required to maintain AI infrastructure including electricity, cooling, maintenance, and facility overhead. These expenses compound over multi-year periods and often exceed initial hardware acquisition costs for large-scale deployments.
Power consumption differs dramatically between TPU and GPU platforms:
- TPU v4 units — consume 175-250 watts per chip
- High-end GPUs — draw 300-400 watts, with flagship models like H100 reaching 700 watts under maximum load
- Large cluster impact — A 512-accelerator cluster running continuously would consume 1.2-1.6 megawatts for TPUs versus 2.0-2.6 megawatts for GPUs
Cooling infrastructure represents 30-40 percent of total data center power consumption. High-performance GPUs generate substantial heat requiring advanced cooling solutions including liquid cooling systems.
Energy Efficiency and Environmental Considerations
The environmental impact of AI hardware has become a central concern as organizations deploy large-scale artificial intelligence systems. Training massive AI models now requires enormous amounts of electricity, with some projects consuming energy equivalent to hundreds of GPU-years.
Power Consumption Differences
TPUs demonstrate substantially better energy efficiency compared to GPUs for AI-specific workloads. AI accelerators designed specifically for neural network operations can achieve 100 to 1,000 times better energy efficiency than general-purpose GPUs.

Source: ResearchGate
TPUs consume approximately 30-50 percent less power than comparable GPU setups while delivering similar or superior performance for many AI tasks. The systolic array architecture in TPUs minimizes memory access operations, which consume significant power in traditional processors.
GPUs require more power because they include hardware components designed for diverse computational tasks beyond AI. While this versatility provides value across multiple use cases, it results in lower energy efficiency for specialized AI workloads.
Cooling Infrastructure Requirements
Thermal design power (TDP) represents the maximum amount of heat a processor generates under typical operating conditions. Data centers must remove this heat to prevent hardware damage and maintain reliable operation.
High-performance GPUs generate substantial heat due to their higher power consumption characteristics. Modern data center GPUs can produce 300-700 watts of thermal output, requiring sophisticated cooling solutions.
TPUs produce less heat because of their lower power consumption, simplifying cooling infrastructure requirements. Many TPU deployments include liquid cooling as a standard feature, which efficiently removes heat while minimizing facility-level cooling costs.
Software Ecosystem and Framework Compatibility
The software ecosystem surrounding AI accelerators determines how easily developers can build, debug, and deploy machine learning models. TPUs and GPUs offer different levels of support for programming languages, development tools, and machine learning frameworks.
CUDA vs Google AI Platform Integration
CUDA represents NVIDIA’s parallel computing platform and programming model that transforms GPUs into general-purpose processors. CUDA enables developers to write programs in C, C++, Python, and other languages to run computations on NVIDIA GPUs.
Google’s AI platform centers around TensorFlow, JAX, and the Pathways runtime environment. TensorFlow provides a comprehensive framework for building and training machine learning models, while JAX offers composable transformations for high-performance scientific computing.
CUDA supports virtually any programming language through bindings and wrappers, making it accessible to developers with diverse backgrounds. Google’s platform focuses primarily on Python with some C++ support, emphasizing integration with machine learning workflows.
Framework Support Differences
Framework compatibility varies significantly between TPUs and GPUs, affecting which tools developers can use for their projects.
Source: The Savvy Canary
GPU Framework Support:
- TensorFlow with full native support and GPU acceleration
- PyTorch with complete native support and CUDA integration
- JAX with native GPU support through XLA compilation
- ONNX with broad compatibility for model interchange
TPU Framework Support:
- TensorFlow as the primary framework with full optimization
- JAX with native support and XLA compilation for TPUs
- PyTorch with limited support through PyTorch/XLA bridge
- Other frameworks with minimal or no direct support
TPUs work best with TensorFlow and JAX, where Google has invested heavily in optimization. PyTorch support exists through the XLA (Accelerated Linear Algebra) compiler but remains less mature than GPU implementations.
Optimal Use Cases for TPUs vs GPUs
Choosing between TPUs and GPUs depends on your specific workload, budget, and infrastructure requirements. TPUs excel at tasks involving heavy matrix operations and transformer architectures, while GPUs offer versatility across diverse AI applications.
Source: Semiconductor Engineering
Natural Language Processing and Transformers
TPUs demonstrate exceptional performance for natural language processing tasks because transformer architectures rely heavily on attention mechanisms and matrix operations that align perfectly with TPU design. Attention mechanisms calculate relationships between every word in a sentence through multiple tensor operations.
Training BERT models on TPUs completes approximately 8 times faster than equivalent GPU setups, with similar speedups observed for GPT-style models. Google Translate processes billions of translation requests daily using TPUs, demonstrating the architecture’s capability for production-scale language processing.
GPUs remain competitive for NLP tasks requiring custom operations, complex preprocessing pipelines, or frameworks beyond TensorFlow and JAX. Teams working with PyTorch may find better ecosystem support and debugging tools with GPU platforms.
Computer Vision and Image Recognition
Computer vision performance varies significantly between TPUs and GPUs depending on model architecture and specific requirements. TPUs excel at training convolutional neural networks like ResNet-50 and EfficientNet, showing 1.5-1.9x faster training throughput compared to equivalent GPU configurations.
For image classification tasks using standard architectures, TPUs provide clear advantages in training speed and energy efficiency. Training ResNet-50 on CIFAR-10 for 10 epochs takes approximately 15 minutes on TPU v3 compared to 40 minutes on NVIDIA Tesla V100.
GPUs maintain advantages for computer vision workflows requiring custom operations, complex data augmentation, or integration with graphics rendering pipelines. Real-time inference applications present mixed results, with Edge TPUs processing 400-1,000 frames per second while consuming only 0.5 watts.
Recommendation Systems and Sparse Models
Recommendation systems present unique computational challenges that favor different architectures depending on model design. TPU v5p includes specialized SparseCores designed specifically for embedding-intensive models common in recommendation systems, providing 1.9x faster training compared to TPU v4 for these workloads.
Large embedding tables — the foundation of modern recommendation systems — require efficient sparse operations that SparseCores handle well. GPU performance for recommendation systems varies based on embedding size and sparsity patterns.
Organizations training large-scale recommendation models with hundreds of millions of parameters often find TPU cost efficiency compelling, particularly when using TensorFlow or JAX. For businesses implementing AI in call centers or AI for sales, recommendation system performance directly impacts customer experience quality.
Frequently Asked Questions About TPUs vs GPUs
Can you use TPUs outside of Google Cloud?
Cloud TPUs remain exclusively available through Google Cloud Platform. Google does not sell TPU hardware directly to customers or allow TPU deployment on other cloud providers like AWS or Microsoft Azure.
Edge TPUs provide an alternative for specific use cases. Google sells Edge TPU development boards and modules that developers can purchase and deploy in their own hardware systems. Edge TPUs consume only 0.5 watts and can process 400-1,000 frames per second.
How long does it take to migrate from GPU to TPU infrastructure?
Migration timelines typically range from 2-6 months depending on code complexity and team experience. Simple models using standard TensorFlow operations often migrate within 2-4 weeks, while custom CUDA kernels or PyTorch models require 2-3 months of development work.
TensorFlow models usually require minimal changes since TPUs integrate natively with TensorFlow. PyTorch models need conversion to use PyTorch/XLA, which may not support all PyTorch features identically.
Do TPUs support all machine learning frameworks equally?
TPUs provide primary optimization for Google’s frameworks including TensorFlow and JAX. These frameworks integrate directly with TPU hardware and receive the most comprehensive feature support and performance optimization from Google’s engineering teams.
PyTorch support exists through PyTorch/XLA but remains less mature than native GPU support. Some advanced PyTorch features may not function identically on TPU hardware. Other frameworks like MXNet, Caffe, and domain-specific tools have limited or no TPU support.
What happens if you need to scale beyond a single accelerator?
Both TPUs and GPUs support distributed training across multiple accelerators, but they use different approaches. TPU Pods can scale to thousands of chips with custom interconnects optimized for synchronous training. The largest TPU v4 Pods contain 4,096 chips connected through Google’s custom Inter-Chip Interconnect.
GPU clusters typically scale to hundreds of accelerators using standard networking protocols like InfiniBand. NVIDIA’s NVLink provides direct GPU-to-GPU communication within servers, while NVSwitch fabric connects multiple GPUs in all-to-all communication patterns.
The choice between platforms affects scaling strategies. TPU Pods excel at massive synchronous training workloads but require commitment to Google Cloud Platform. GPU clusters offer more flexibility in deployment locations and configuration options.

