An AI vector database stores and retrieves high-dimensional numerical representations of data to enable fast similarity searches for artificial intelligence applications.
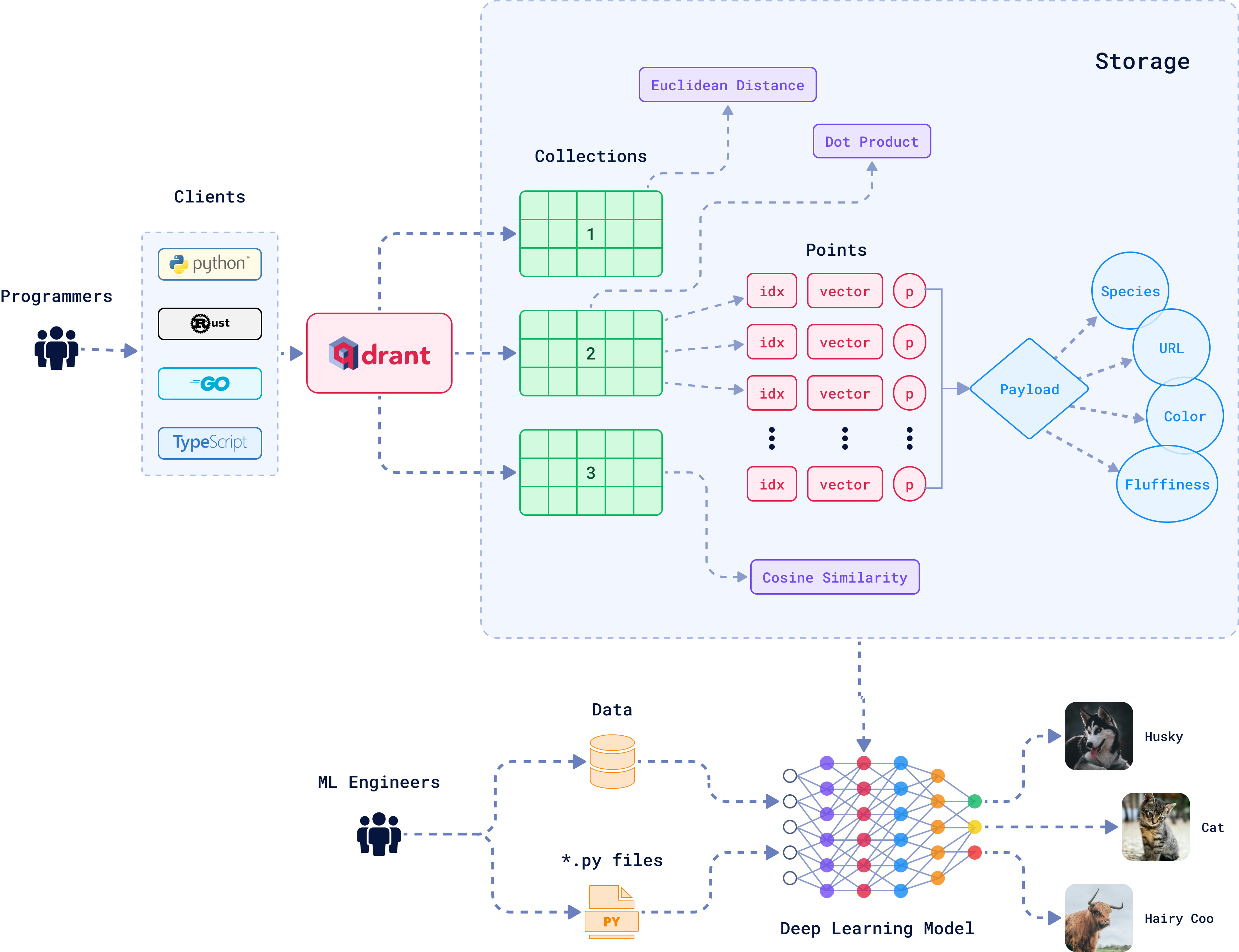
Source: Qdrant
Modern AI systems process vast amounts of unstructured data including text, images, audio, and video. Traditional databases struggle with this type of content because they organize information in rows and columns designed for structured data. AI vector databases solve this problem by converting unstructured data into mathematical representations called vectors.
These vectors capture the semantic meaning of content in numerical form. Similar items produce vectors that cluster close together in high-dimensional space. When users search for information, the database compares query vectors against stored vectors to find the most similar matches.
Vector databases power many AI applications that people encounter daily. Search engines use vector similarity search to understand the intent behind queries. Recommendation systems rely on vector databases to suggest relevant content. AI agents and assistants use vector databases to find relevant information when answering questions.
How AI Vector Databases Work

Source: Medium
Vector databases convert different types of content into numerical arrays called embeddings. Each embedding contains hundreds or thousands of numbers that represent the semantic properties of the original data. AI models called embedding models perform this conversion process.
For example, the sentence “The weather is sunny today” might become a vector with 1,536 dimensions. Each dimension captures different aspects of meaning, relationships, and context. Similar sentences produce vectors with similar numerical patterns.
The database organizes these vectors using specialized indexing methods. Traditional databases use indexes like B-trees that work well for exact matches. Vector databases use algorithms like Hierarchical Navigable Small World graphs that efficiently find approximate matches in high-dimensional space.
Distance metrics determine how the database measures similarity between vectors. Cosine similarity compares the angle between vectors. Euclidean distance measures the straight-line distance between points. Different metrics work better for different types of data and applications.
Vector Databases vs Traditional Databases

Source: Capella Solutions
Traditional databases excel at storing structured information in predefined formats. They use SQL queries to find exact matches or ranges of values. Vector databases optimize for approximate similarity searches across unstructured data.
Storage approaches differ significantly between the two systems. Traditional databases organize data in tables with rows and columns. Vector databases store high-dimensional arrays and focus on spatial relationships between data points.
Query patterns also vary substantially. Traditional databases answer questions like “Find all customers in California with orders over $1,000.” Vector databases answer questions like “Find documents similar to this research paper” or “Show products related to this image.”
Performance characteristics reflect these different purposes:
- Traditional databases — Optimize for transaction processing and complex joins across multiple tables
- Vector databases — Optimize for fast similarity searches across millions or billions of vectors
- Query speed — Vector search proves faster for AI tasks because it avoids complex JOIN operations
Common Vector Database Use Cases

Source: AIML.com
Retrieval-augmented generation represents one of the most important applications for vector databases. Large language models lack access to current information or proprietary data. Vector databases enable AI systems to find relevant context from knowledge bases and include this information in responses.
Semantic search applications use vector databases to understand user intent rather than matching exact keywords. Users can search for “climate change effects” and find documents about “global warming impacts” even when those exact words don’t appear in the query.
Recommendation engines rely on vector databases to identify similar users, products, or content. E-commerce platforms use vector databases to suggest products based on browsing history and purchase patterns. AI in customer experience applications enable personalized recommendations across streaming services for movies and shows using vector representations of user preferences.
Image and multimodal search applications enable queries across different content types. Users can upload photos to find similar products or search for images using text descriptions. Modern embedding models can represent text, images, and audio in the same vector space.
Key Benefits of Vector Databases

Source: ResearchGate
Vector databases handle exponential data growth through horizontal scaling architectures that distribute workloads across multiple nodes. These systems maintain consistent query performance even as datasets expand from millions to billions of vector embeddings.
Traditional databases struggle with unstructured data that grows at 30 to 60 percent annually. Vector databases address this challenge by converting unstructured content into queryable vector representations that scale efficiently with data volume increases.
Query response times remain in milliseconds across datasets containing billions of vectors. Advanced indexing algorithms enable near-instantaneous similarity searches that would require hours using traditional linear search methods.
Vector databases integrate directly with popular AI frameworks including LangChain, which provides connections to over 25 embedding methods and 50 different vector storage options. Cloud providers offer native integrations with services like Amazon Bedrock, Azure OpenAI, and Google Cloud AI platforms.
Popular Vector Database Platforms
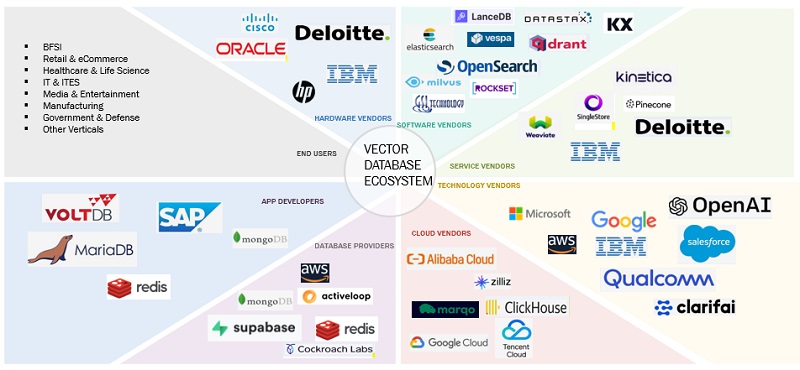
Source: MarketsandMarkets
Organizations can choose from three primary categories of vector database solutions. Each category offers distinct advantages for different enterprise requirements and technical capabilities.
Commercial vector database platforms provide comprehensive feature sets designed for large organizations. Companies like Pinecone, Weaviate, and Qdrant offer purpose-built vector databases that include advanced indexing algorithms, enterprise-grade security controls, and professional support services.
Community-driven vector database projects offer organizations the flexibility to customize implementations while controlling licensing costs:
- Chroma — Open-source vector database with Python integration
- Milvus — Scalable vector database for production environments
- pgvector — PostgreSQL extension for vector storage and search
Major cloud providers offer managed vector database services that integrate with their broader AI ecosystems. Amazon Web Services provides vector search through Amazon OpenSearch Service, while Microsoft Azure offers vector support through Azure Cosmos DB and Azure AI Search.
Implementation Planning and Considerations
Organizations planning vector database adoption face three critical areas requiring careful evaluation. Implementation success depends on proper infrastructure planning, robust security frameworks, and strategic performance optimization.
Vector databases demand substantial computational resources due to their high-dimensional data processing requirements. Memory represents the most critical component, as many indexing algorithms require keeping significant portions of vector data in RAM for acceptable query speeds.
Modern vector database deployments typically require 16-32 GB of RAM as a baseline, with enterprise systems often needing hundreds of gigabytes or more. The exact memory requirements depend on vector count, embedding dimensions, and chosen indexing algorithms.
Security and data governance present unique challenges beyond traditional database protection mechanisms. Embedding models can inadvertently encode sensitive information within vector representations, creating potential privacy vulnerabilities that require specialized mitigation approaches.
Access control systems accommodate vector similarity search patterns where query results depend on relationships across the entire vector space. Traditional row-level security approaches don’t translate directly to vector databases, requiring new frameworks that associate permissions with individual vectors or vector subsets.
Getting Started With Vector Databases

Source: Openxcell
The implementation process starts with data assessment and preparation. Teams evaluate existing data sources, determine which content will be converted to vector embeddings, and establish data quality standards. This phase involves selecting appropriate embedding models based on the types of data and required accuracy levels.
Technical architecture decisions follow data preparation. Organizations choose between cloud-managed services versus self-hosted solutions based on control requirements, cost considerations, and existing infrastructure. The architecture accounts for embedding generation pipelines, vector storage requirements, and query processing capabilities.
Performance optimization involves tuning indexing algorithms and query parameters to meet latency and accuracy requirements. HNSW indexes require configuration of connection parameters and search precision settings. Organizations typically start with conservative settings and gradually optimize based on actual query patterns.
Testing and validation procedures verify that vector search results meet quality expectations. Teams establish baseline performance metrics, conduct accuracy testing with representative queries, and validate that similarity search returns relevant results. AI maturity assessments help organizations evaluate their readiness for vector database implementation.
Frequently Asked Questions
What’s the difference between a vector database and a vector index?
A vector database functions as a complete data management system that stores vectors, handles updates, manages metadata, and provides full database capabilities like backup, recovery, and user management. A vector index focuses solely on organizing vectors for fast similarity searches without offering storage or management features.
Think of a vector database as a full library system with books, cataloging, checkout processes, and librarians. A vector index works like just the card catalog — it helps you find what you’re looking for quickly, but it doesn’t actually store the books or manage the library operations.
How do you measure vector search accuracy in practice?
Vector search systems use several metrics to evaluate performance. Recall measures what percentage of relevant results the system finds — if 100 relevant documents exist and the system finds 80, recall equals 80 percent. Precision measures what percentage of returned results are actually relevant.
User satisfaction scores track whether search results meet user expectations through feedback and behavior analysis. Application-specific metrics matter most — e-commerce sites might track click-through rates on recommended products, while document search systems might measure how often users find their target information.
What happens when you need to update embedding models?
Changing embedding models requires regenerating all existing vectors using the new model. Old vectors become incompatible with new vectors because different models create different numerical representations for the same content. Organizations plan for data migration periods and temporary service disruptions.
The process involves running content through the new embedding model, replacing old vectors with new ones, and updating search indexes. Large datasets might require days or weeks to process completely. Organizations often maintain parallel systems during transitions to minimize downtime and test new model performance.
Can vector databases replace traditional databases entirely?
Vector databases excel at specific tasks but can’t replace traditional databases entirely. Vector databases perform similarity searches efficiently and power AI applications like recommendation systems and semantic search. Traditional databases handle structured data, financial transactions, and complex relationships between data points more effectively.
Most organizations use both types of databases. Traditional databases manage customer information, inventory, and financial records. Vector databases handle AI features like product recommendations and content search. The two systems often work together, with traditional databases storing business data and vector databases enabling intelligent features powered by AI agents.
How much does implementing a vector database typically cost?
Implementation costs depend on several key factors. Data volume affects storage requirements, with larger datasets requiring more expensive infrastructure. Query frequency determines computational needs, as systems handling millions of searches daily require more processing power than those with occasional queries.
Cloud services typically charge based on usage, with costs ranging from hundreds to thousands of dollars monthly for enterprise deployments. Self-hosted solutions require upfront hardware investments and ongoing maintenance expenses. Organizations processing millions of vectors might spend $5,000-$50,000 monthly, while smaller deployments could cost $500-$5,000 monthly.
Vector database technology continues evolving rapidly as organizations increasingly adopt AI-driven applications that require sophisticated similarity search capabilities. The growing integration of vector databases with foundation models and large language models positions these systems as fundamental infrastructure for the next generation of intelligent applications.
Organizations that begin implementing vector database capabilities now position themselves to capitalize on these trends while building competitive advantages through superior AI-powered user experiences. Professional AI consulting services can help businesses evaluate their specific needs and develop comprehensive implementation strategies for vector database adoption.

