AI accelerators are specialized computer chips designed specifically for artificial intelligence tasks, while GPUs (Graphics Processing Units) are more versatile processors that can handle AI work alongside other computing tasks.
The choice between AI accelerators and GPUs affects how fast organizations can process machine learning models and how much energy their systems consume. AI accelerators excel at specific neural network operations but cannot adapt to different types of work. GPUs offer more flexibility but use more power for the same AI tasks.

Source: Semiconductor Engineering
Understanding these differences helps technology leaders make informed decisions about hardware investments. Each option serves different needs depending on the organization’s AI goals and existing infrastructure.
Modern AI systems require massive computational power to train models and process data. The hardware choice impacts everything from project timelines to electricity bills, making the accelerator versus GPU decision increasingly important for businesses implementing artificial intelligence solutions.
What Are AI Accelerators
AI accelerators are purpose-built computer chips that handle artificial intelligence calculations exclusively. Unlike regular processors that juggle many different computing tasks, AI accelerators focus only on the math operations that power machine learning algorithms.
These specialized chips eliminate the computational overhead that general-purpose processors carry. Traditional processors excel at diverse tasks but sacrifice efficiency when running AI operations. AI accelerators solve this problem by incorporating custom circuits, specialized instruction sets, and memory systems designed specifically for neural networks.
Application-Specific Integrated Circuits (ASICs) represent the most specialized type of AI accelerator. Engineers design ASICs for specific AI functions like image recognition or language processing. These chips achieve maximum efficiency by implementing fixed circuits that perform exact calculations without unnecessary overhead. However, ASICs can’t be reprogrammed after manufacturing, which limits their adaptability to new algorithms.
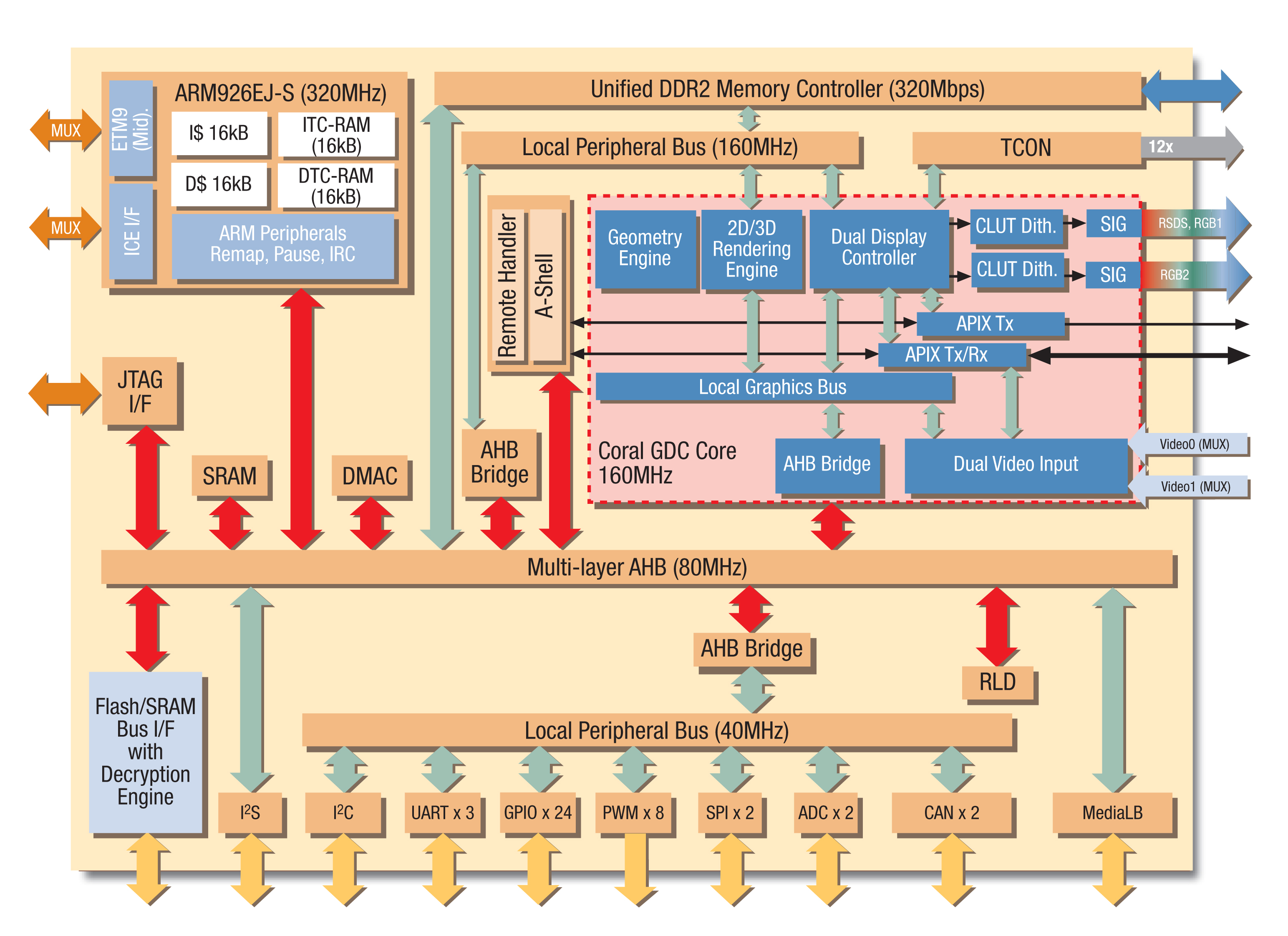
Source: ChipVerify
Tensor Processing Units (TPUs) are Google’s AI accelerators optimized for tensor operations — the mathematical foundation of neural networks. TPUs use systolic array architecture that allows data to flow through processing elements in synchronized patterns. This design reduces complex control logic and maximizes computational throughput for AI tasks.
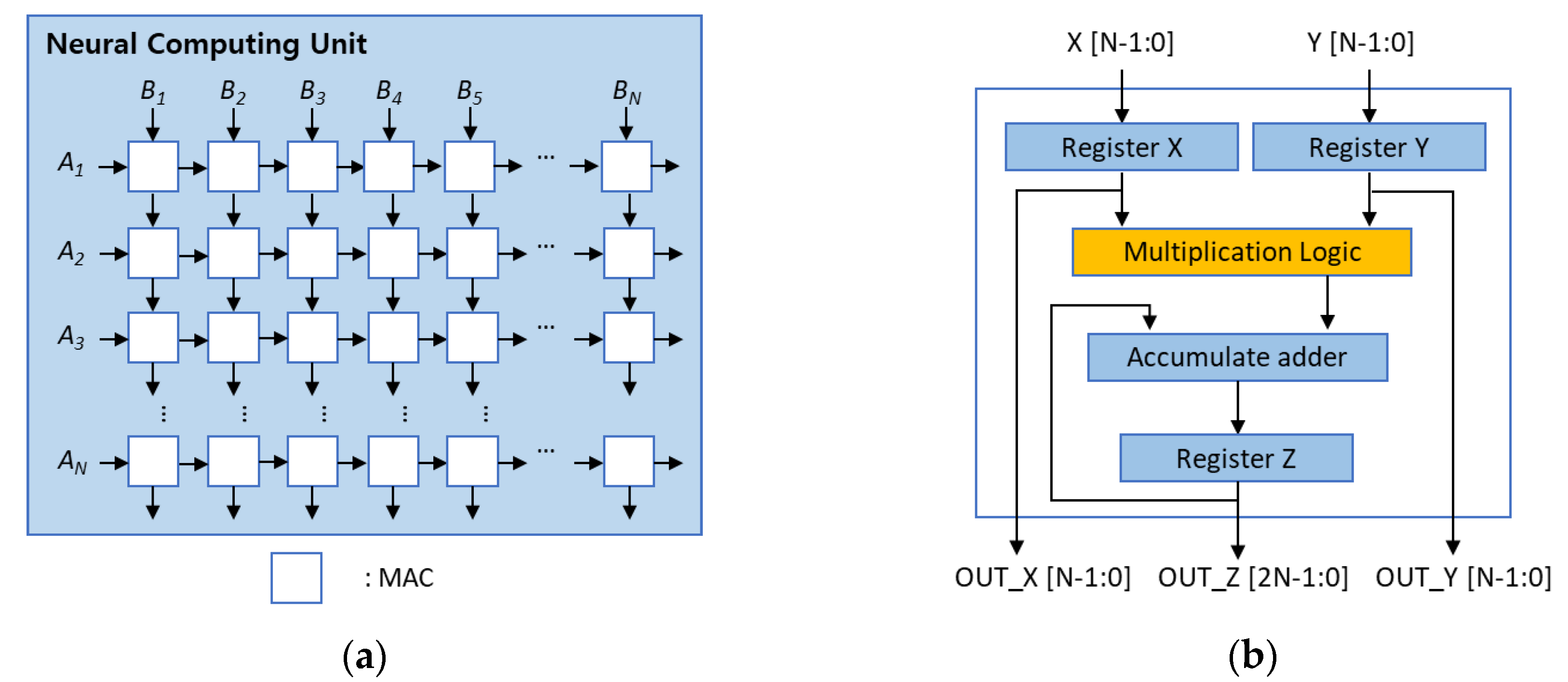
Source: MDPI
Understanding GPU Architecture for AI
Graphics Processing Units evolved from rendering video game graphics to become powerful AI processors. GPUs contain thousands of small processing cores that can perform calculations simultaneously, making them highly effective for the parallel math operations required in machine learning.
The transition from graphics to AI happened because both applications require similar parallel computation. When rendering graphics, GPUs process millions of pixels at once. AI applications perform similar parallel calculations when processing data through neural networks.
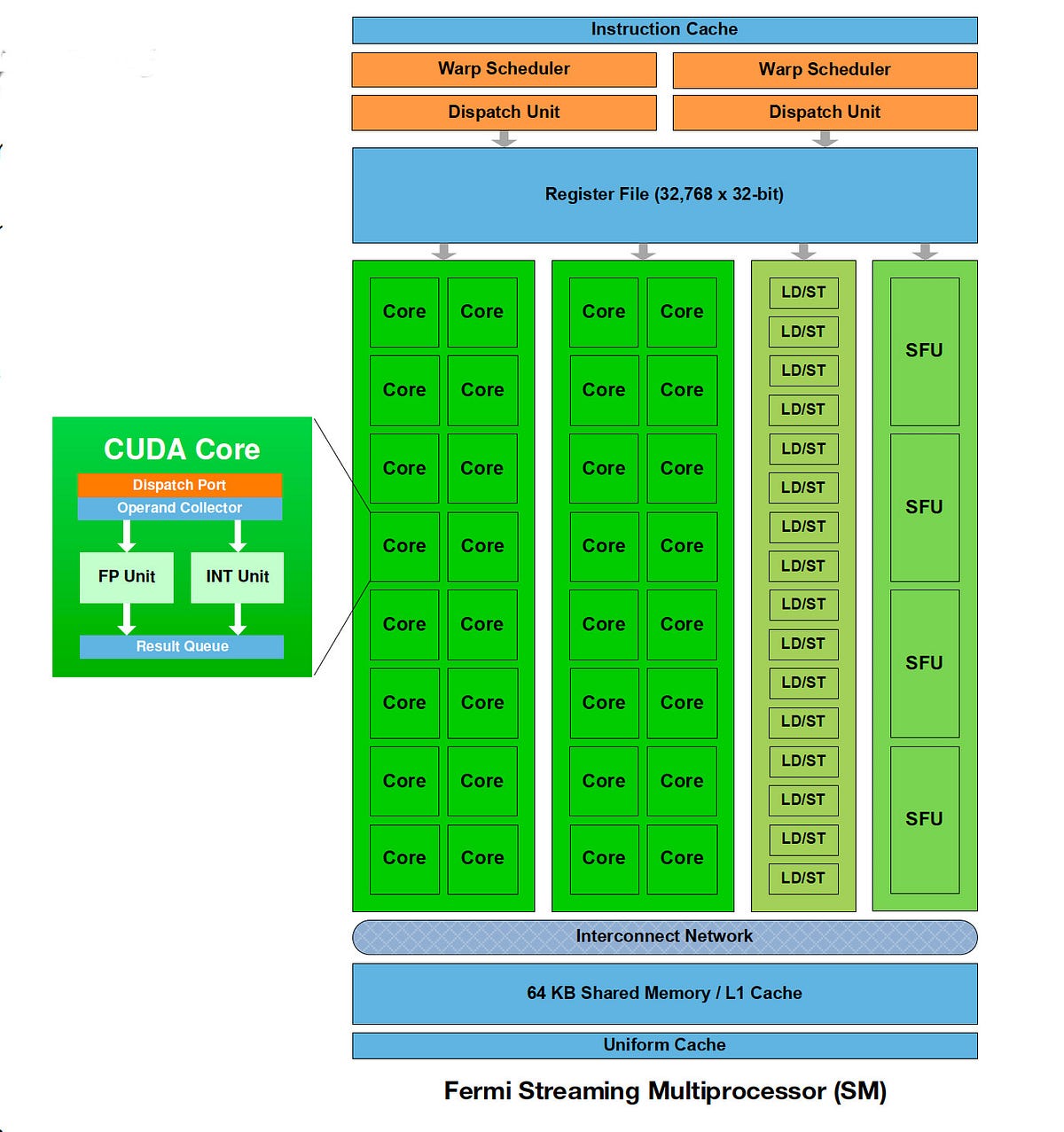
Source: Medium
Modern GPUs organize their thousands of cores into groups called streaming multiprocessors. Each core handles simple calculations independently while working together to process large datasets. A typical AI-focused GPU contains 2,000 to 10,000 cores, compared to a CPU’s 4 to 64 cores.
CUDA programming platform enables developers to use NVIDIA GPU cores for AI tasks beyond graphics. CUDA provides tools and libraries that translate AI operations into efficient GPU instructions. Popular AI frameworks like TensorFlow and PyTorch integrate directly with CUDA to automatically transfer intensive operations from the CPU to the GPU.
Key Technical Differences
AI accelerators and GPUs take fundamentally different approaches to processing artificial intelligence workloads. Understanding these differences explains why each technology excels in specific scenarios.
Architecture philosophy differs significantly between these technologies:
- AI accelerators — Fixed-function hardware units optimized for specific operations like matrix multiplication
- GPUs — Programmable architecture supporting multiple types of parallel processing tasks
- AI accelerators — Custom instruction sets designed specifically for neural network computations
- GPUs — General-purpose instruction processing that adapts to diverse algorithms
Energy efficiency represents AI accelerators’ biggest advantage. Research shows AI accelerators can deliver 10 to 100 times greater energy efficiency compared to GPUs when processing specific AI tasks. This efficiency comes from eliminating unnecessary computational overhead and optimizing power consumption for targeted operations.
GPUs demonstrate strong parallel processing capabilities that benefit machine learning’s inherently parallel nature. Modern GPUs process multiple data streams simultaneously through thousands of cores, enabling efficient batch processing of AI workloads.
Memory architecture varies substantially between technologies. AI accelerators implement specialized memory hierarchies optimized for neural network data access patterns. Advanced systems like TPU v4 achieve memory bandwidth up to 2.5TB/s while optimizing specifically for tensor operations. GPUs evolved from graphics requirements, resulting in memory designs optimized for high-throughput parallel data access with bandwidth up to 7.8 TB/s.
Performance Comparison for AI Workloads
Performance differences between AI accelerators and GPUs depend heavily on the specific type of AI work being performed. Each technology shows distinct advantages in different scenarios.
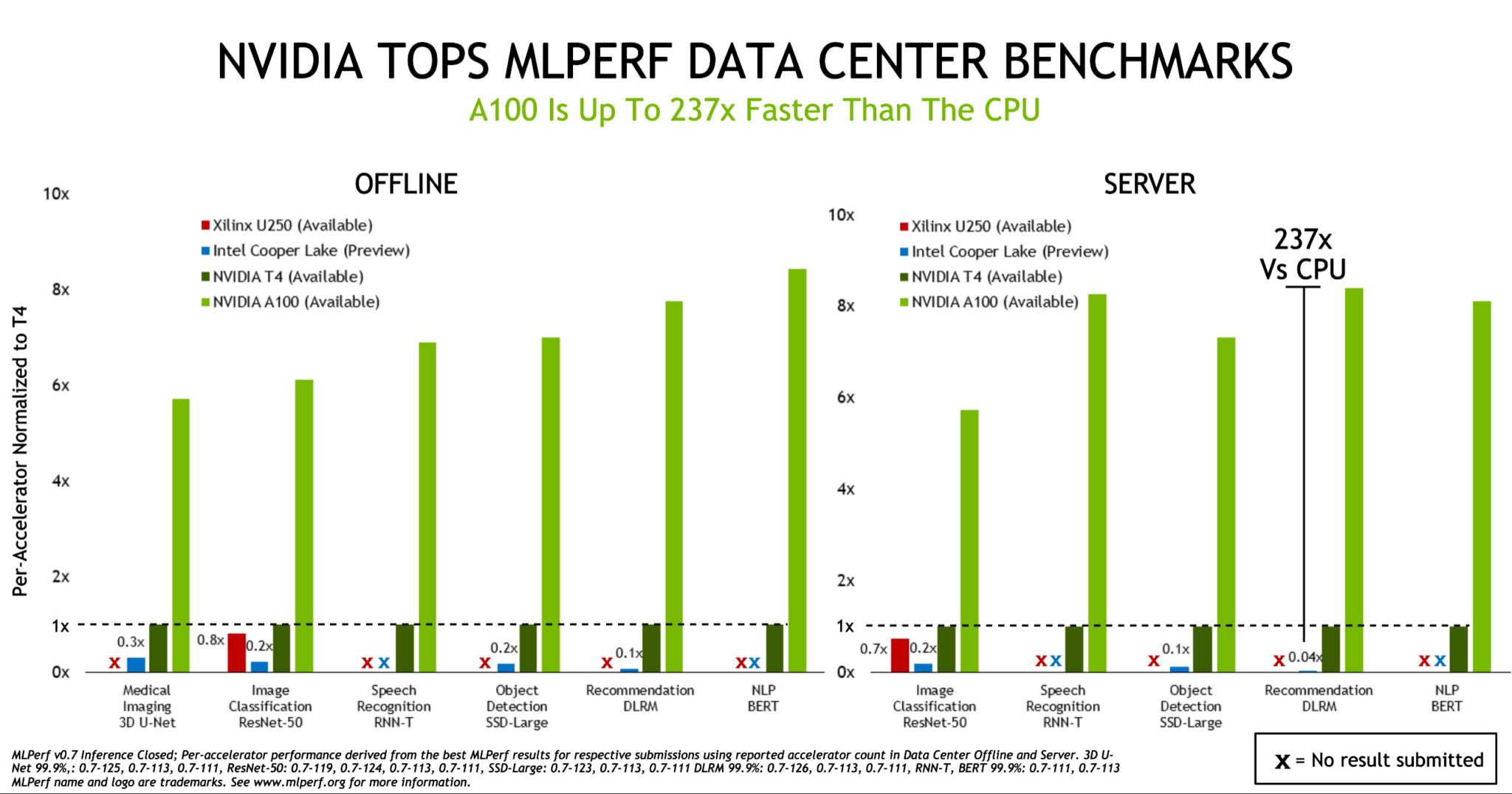
Source: NVIDIA Blog
Training performance typically favors GPUs due to their flexible, programmable architecture. Training deep learning models requires adaptability to handle various neural network architectures and experimental algorithms. GPUs can achieve training performance improvements of over 10 times compared to CPU-based systems through their parallel processing capabilities.
AI accelerators face limitations in training scenarios because their specialized hardware pathways optimize for fixed operations rather than the dynamic requirements of training algorithms. Research environments favor GPUs for training applications where flexibility to experiment with novel algorithms provides strategic advantages.
Inference processing represents where AI accelerators demonstrate superior performance. Large-scale inference deployments benefit significantly from AI accelerator specialization, particularly in data center applications processing massive AI workloads.
Latency becomes critical in real-time applications like autonomous vehicles where computer vision algorithms must process information within strict timing constraints. AI accelerators provide predictable, low-latency processing by eliminating computational overhead associated with general-purpose instruction processing.
Energy Efficiency and Cost Analysis
Energy consumption creates significant ongoing expenses that compound over years of operation. Understanding these costs helps organizations make informed hardware decisions.
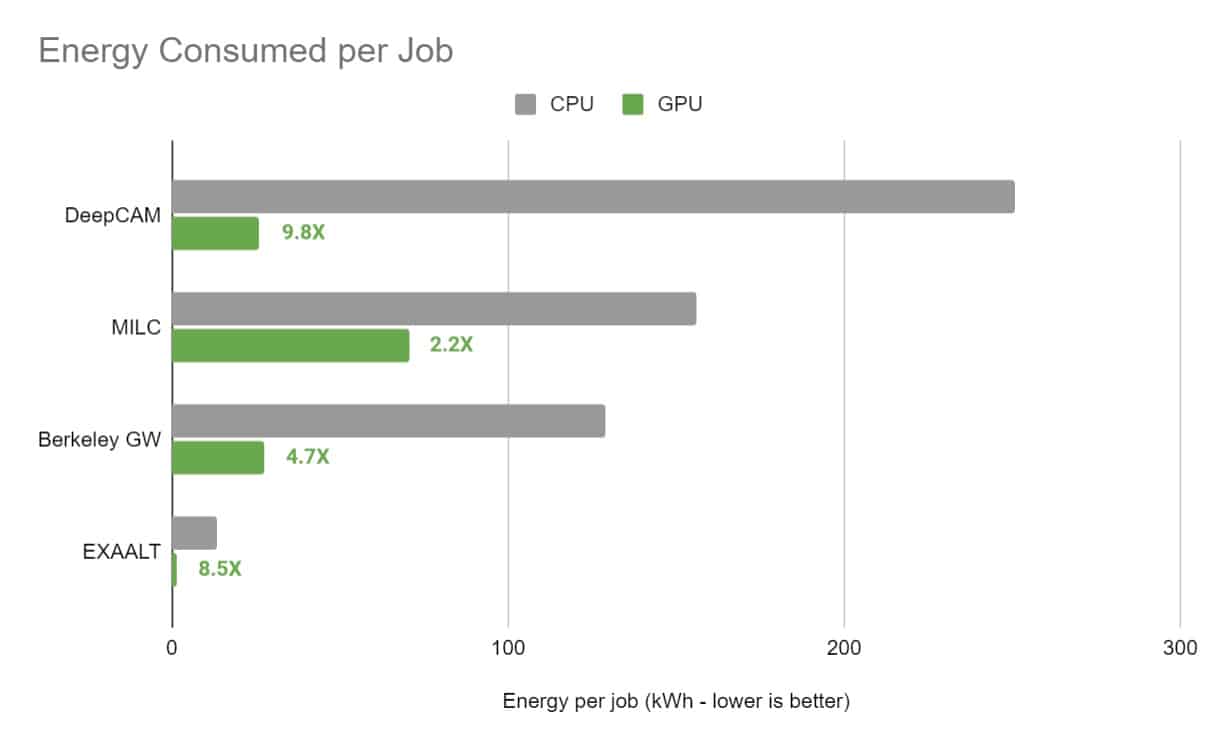
Source: NVIDIA Blog
Power consumption differences are dramatic between these technologies. AI accelerators consume 10 to 100 times less energy than GPUs when processing identical AI tasks. GPUs typically draw 250-450 watts during intensive AI operations, while comparable AI accelerators often operate at 75-150 watts for similar workloads.
Thermal management requirements differ substantially. GPUs generate considerable heat during parallel processing, requiring robust cooling systems with multiple fans or liquid cooling solutions. AI accelerators produce less heat due to optimized power consumption, often requiring simpler air cooling systems.
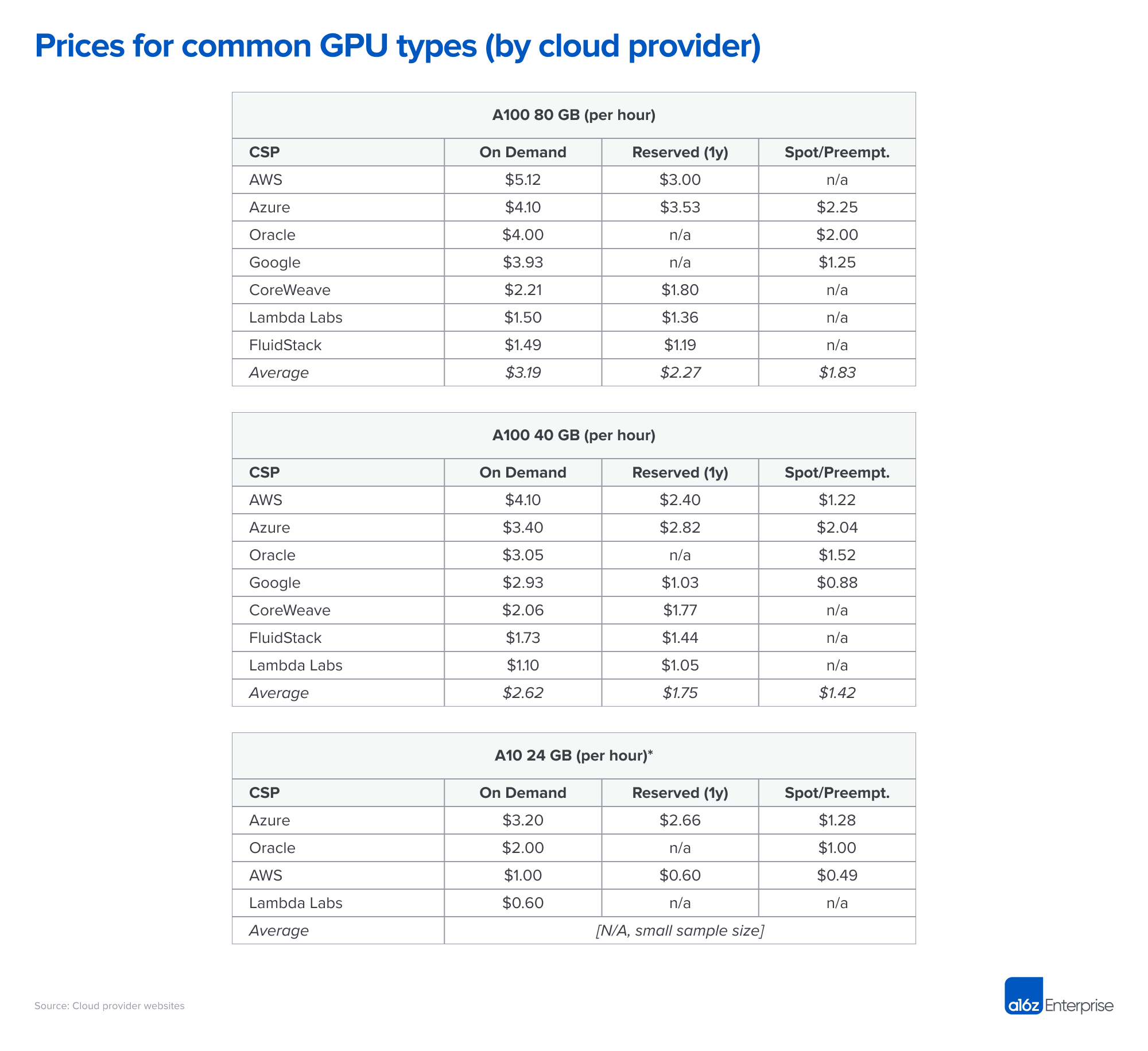
Source: Andreessen Horowitz
Operational cost considerations extend beyond electricity consumption. A single high-performance GPU running continuously can cost $500-1,200 annually in electricity, depending on local power rates. Comparable AI accelerators often cost $150-400 annually for similar processing capabilities.
Cooling requirements multiply electricity expenses beyond direct hardware consumption. Data centers typically spend an additional 30-50 percent of hardware power consumption on cooling systems. GPU deployments requiring 1,000 watts of computing power often demand 300-500 watts of additional cooling capacity.
Choosing the Right Technology for Your Organization
The choice between AI accelerators and GPUs depends on your organization’s computational workload patterns, budget constraints, and flexibility requirements.

Source: Tim Dettmers
AI accelerators provide optimal value in specific scenarios:
- Large-scale inference deployments processing thousands of requests daily
- Edge computing applications in battery-powered devices requiring local AI processing
- Production systems with standardized algorithms like quality control or medical imaging
- Real-time applications where consistent latency and energy efficiency are critical
GPUs offer superior solutions in environments requiring computational flexibility:
- Research and development environments experimenting with novel AI techniques
- Training large language models and deep neural networks
- Mixed workload environments where AI coexists with other computational tasks
- Software development teams building AI applications requiring algorithmic modifications
Organizations developing cutting-edge AI techniques benefit from GPU programmability that enables experimentation without hardware constraints. Research laboratories leverage GPU flexibility to prototype new approaches and investigate emerging algorithms.
Hybrid infrastructure approaches combine both technologies to leverage each one’s strengths. Data centers deploy accelerators for production inference services while maintaining GPU clusters for model training and research activities. This approach optimizes operational efficiency for stable AI workloads through accelerators while maintaining strategic flexibility for innovation through GPU resources.
Implementation Planning
Enterprise AI hardware deployment requires systematic evaluation of computational requirements, infrastructure readiness, and strategic goals before making investments.
Technical requirements assessment starts with analyzing current workloads and projected AI demands. Organizations evaluate whether existing network infrastructure, storage systems, and compute resources can support AI hardware integration without performance bottlenecks.
Power and cooling assessments determine facility readiness. High-performance AI accelerators can consume 400-700 watts per unit, while enterprise GPUs may require 300-500 watts each. Data centers must verify adequate electrical capacity and cooling systems to maintain optimal operating temperatures.
Skills and expertise planning varies significantly between technologies. GPU implementation builds on existing parallel computing knowledge that many technical teams possess. AI accelerator deployment demands specialized knowledge of custom instruction sets and optimization techniques specific to particular hardware architectures.
Training programs typically span 3-6 months for GPU implementations and 6-12 months for AI accelerator deployments, depending on team experience levels. Organizations plan for productivity ramp-up periods during which efficiency gradually increases as expertise develops.
Frequently Asked Questions
Can AI accelerators run the same software as GPUs?
No, AI accelerators typically require specialized software and cannot run standard GPU applications. AI accelerators use custom instruction sets and proprietary development environments that differ from GPU programming models like CUDA or OpenCL. Organizations implementing AI accelerators often need custom software development or framework modifications.
Which technology provides better price-to-performance for machine learning inference?
AI accelerators typically provide better price-to-performance for high-volume, consistent inference workloads due to their energy efficiency advantages. However, GPUs may offer better value for organizations with variable workloads or those requiring flexibility to handle different types of AI models.
How do cloud-based AI services compare to on-premises hardware?
Cloud services offer access to specialized AI hardware without upfront capital investments, transferring hardware obsolescence risks to cloud providers. On-premises installations provide direct hardware control and potentially lower operational costs for organizations with predictable, high-volume AI workloads.
What level of technical expertise do organizations need for AI accelerator implementation?
AI accelerator implementation typically requires specialized engineering resources or consulting support due to custom optimization approaches and proprietary development environments. The limited software ecosystem creates additional complexity compared to GPU implementations that benefit from mature development tools and extensive community resources.
AI accelerators and GPUs serve different purposes in the artificial intelligence landscape. Organizations running stable, well-defined AI applications benefit from AI accelerators’ specialized efficiency, while those developing new solutions or supporting diverse computational needs find GPUs more suitable. The decision requires careful evaluation of workload patterns, energy costs, and long-term flexibility requirements to optimize both performance and operational expenses.

